10 Consciousness
In this section we would like to discuss to what extent properties of consciousness might be found in our system. Even though we start from a common notion of how consciousness can be viewed as consisting of separable domains, we are well aware that this approach is not the only or ultimate solution for approaching this question. But such a differentiation appears well-suited for our bottom-up approach.
Overall, many authors contribute to the view in which consciousness is broken down into a set of properties. We start from a review by Cleeremans (2005), who gives a good overview on the diverse philosophical views on consciousness and tries to integrate them into one framework. While there is disagreement in general and also on the details (see also Vision 2011), Cleeremans interestingly finds a common denominator between the different opinions that characterize possible computational correlates of consciousness. He introduced a differentiation of consciousness into three domains: phenomenal consciousness, access consciousness, and metacognition (or in other contexts referred to as reflexive consciousness). There is disagreement on the phenomenal aspect, as it is seen by one group of philosophers to be an independent domain. In contrast, there is also a view in which phenomenality cannot be separated from metacognition and access consciousness, but must be seen in relation to those (see review Cleeremans 2005).
We have argued in section 7, that the phenomenal aspect as such, i.e., the property of some neuronal structures that are equipped with subjective experience, has per se no function, but is, nonetheless, not separable from the functional properties. Therefore, we see the phenomenal aspect not as a separate type of consciousness, but as a property of both access consciousness and metacognition. This view has convincingly been supported by Kouider et al. (2010) as well as, in a recent review, by Cohen & Dennett (2011). Therefore, we will compare properties of reaCog with current definitions found in the literature concerning the phenomena of access consciousness and metacognition, abstracting from the phenomenal aspect.
While other philosophers require metacognition or reflexive consciousness in a system in order to attribute consciousness (see for example Rosenthal 2002 or Lau & Rosenthal 2011 for a recent review defending this view), we do not want and cannot get into this discussion as it is not our goal to review the different types of taxonomies. We basically follow one valid and common perspective, as presented by Cleeremans, and apply it to our system in order to analyze functions of our system that can match the different phenomena described. We do not aim with this approach to give a rigorous definition of consciousness (which does not seem suitable at this point, see also Holland & Goodman 2003). Instead, applying our approach, we aim to provide insight into specific functions of our system that are connected to the phenomena discussed.
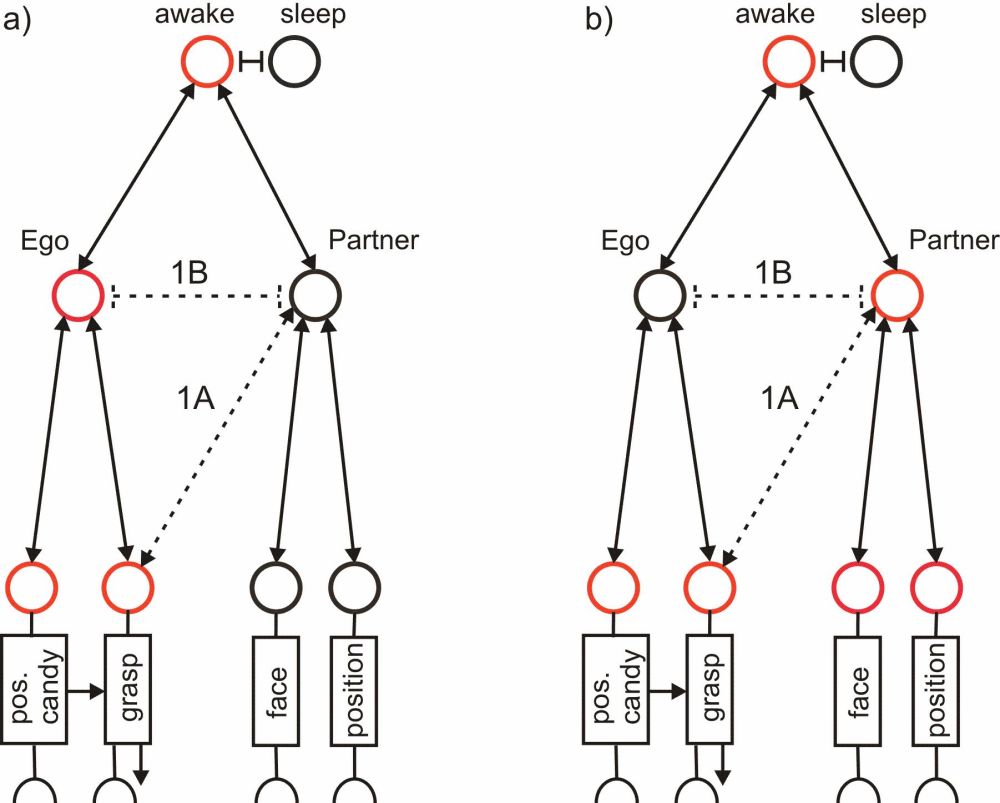 Figure 9: A possible expansion of reaCog. Without the connections 1A and 1B the network enables the agent to represent its own actions, as is already possible for the network shown in figure 2, and figure 6. After introduction of connections 1A and 1B the network is also able to represent the actions of a partner using the now shared procedure “grasp”. (a) and (b) show two attractor states where active motivation units are depicted in red, whereas inactive motivation units are shown in black. Half circles indicate sensory input.
Figure 9: A possible expansion of reaCog. Without the connections 1A and 1B the network enables the agent to represent its own actions, as is already possible for the network shown in figure 2, and figure 6. After introduction of connections 1A and 1B the network is also able to represent the actions of a partner using the now shared procedure “grasp”. (a) and (b) show two attractor states where active motivation units are depicted in red, whereas inactive motivation units are shown in black. Half circles indicate sensory input.
10.1 Access consciousness
In this section we want to focus on the aspects of access consciousness that can be found in reaCog. Following Cleeremans, access consciousness of a system is defined by the ability to plan ahead, to guide actions, and to reason, as well as to report verbally on the content of internal representations. In contrast, non-conscious representations cannot be used this way. Selecting behaviors, planning ahead, and guiding actions are the central tasks of reaCog (see section 4, Planning ahead).
Being able to use internal representations for verbal report is currently not a part of reaCog. However, the internal representation of reaCog is already suited to allow for accessing internal representations (section 5 and figure 7). The simple solution proposed allows for communication using one-word sentences only, but provides a way, within the framework of reaCog, for the symbol-grounding problem to be addressed. Steels (2007; Steels & Belpaeme 2005) and Narayanan (1997) have already studied in detail how more complex sentences may be grounded in simple reactive systems. Thus, there already exists work on similar systems that shows how the ability to report by using more complex language structures could be implemented in a reactive system. Therefore, at least in principle, this property could be realized in reaCog, too.
The last property describing access consciousness, symbolic reasoning, is not addressed by reaCog. In the symbolic domain, there are, however, many interesting approaches in the literature that might be connected to a system like reaCog after the symbolic level has been implemented.
Concerning related work, Dehaene & Changeux (2011) review relevant network models that are supposed to simulate consciousness, including their own approach, which is termed global neural workspace theory (GNW; see also Seth 2007 for a systematic summary). A comparison of reaCog with these approaches can be found in Cruse & Schilling (2013). Here we will only refer to one important notion, “global availability” as used by several authors to represent a crucial property of access consciousness (e.g., Dehaene & Changeux 2011; Dehaene & Naccache 2001; Baars & Franklin 2007; Cleeremans 2005). Global availability describes the notion that many representations of the system can potentially become conscious. These representations can be selected to solve a current problem (as described for reaCog) or could be selected in a task (see GNW).
Are the representations used in reaCog globally accessible? During execution of a form of behavior the reactive system simply reacts to sensory inputs. Single local modules of the procedural memory are activated by the context, for example, the walking behavior that can execute walking even in a cluttered environment. While the behavior is driven by sensory stimuli, it is not “cognitively attended” and runs automatically in response to direct interaction with the environment. In this case, the representations are not attended by cognitive expansion and are clearly not a part of access consciousness. But, importantly, this can change whenever a problem is detected and the reactive (automatic) system is not sufficient anymore. In such a case, the WTA-net of the attention controller is activated and has to select one of the elements of the procedural memory. During planning, these elements become accessible to the attention system (Norman & Shallice 1986). The WTA-net, which constitutes the essential part of the attention controller, projects directly back to the motivation units of the procedural memories (figure 6, dashed arrows) and thereby selects just one of the possible behaviors (due to the characteristics of a Winner-Take-All network). Therefore, all the procedural modules that could be activated by the attention controller are “globally available” and form possible elements of access consciousness.
10.2 Further relations between reaCog and access consciousness
Another interesting property of reaCog and findings in psychology concern the relation between conscious and automatic procedures. It is well known that humans are able to learn a new behavior by consciously attending to that behavior. Over time, this can change and the execution of the behavior becomes more and more automatic, i.e., it is no longer necessary to be consciously aware of the exact execution of the behavior. A similar shift of attention can be found when reaCog is planning new behaviors. Triggered by the activation of a problem detector, reaCog has to shift its attention towards the new behavior during planning and the following execution of a behavior. As long as the problem-detector is still active, the reactive system is basically suspended (by switching off the loop through the body), and instead the planning system tries out new procedures that have to be attended to. After the successful execution the new solution can also be stored as a procedural memory and become part of the reactive system; it does not require cognitive attention anymore (the procedure how to store this information has not yet been implemented in reaCog). An advantage of this integration into the reactive system is that access to reactive procedures is faster than using the cognitive process, which agrees with the findings mentioned above.
There are other experimental findings highlighting the relation between conscious and non-conscious access to procedural elements. Beilock et al. (2002) found that athletes who have learned a behavior so that it can be performed automatically perform worse when they concentrate on the behavior compared to when performing the behavior while being distracted. In the attention controller of reaCog we can observe a similar phenomenon. If the attention controller is externally activated by a higher-level unit while the connected behavior is performed, this could possibly activate learning. Such an influence would change the underlying neuronal module and could worsen the result. In contrast, without attention the behavior would be performed as it had been learned earlier.
ReaCog differs in an important aspect from the simulation studies conducted by Dehaene and colleagues, as well as from those conducted by Baars and colleagues. While the latter approaches aim to relate conscious functioning to individual brain areas or brain circuits, reaCog is not intended at all as a model of the human brain or any of its areas. Instead, it is envisioned as a reductionist approach that focuses only on function. From the bottom-up development of more and more higher-level function we offer a post-hoc discussion of the question of to what extent reaCog shows aspects of access consciousness. This approach seems particularly suitable for addressing access consciousness, as it turns out that there is no single identifiable part of reaCog that might be attributed the property of access consciousness. Instead, access consciousness appears to be an emergent property constituted by the complete system. Attention controller, procedural memory, and the connections between those two parts, as well as the internal model and the ability to use it in internal simulation, seem to be the required structures that allow access consciousness, or, in other words, together constitute the “neural workspace.” The dynamics of the neural workspace as defined by Dehaene & Naccache (2001) are given through the WTA-net. But, and this is an important difference, there no re-representation in this neural workspace is necessary. The already-present representations can be reused in novel contexts. The existing modules of procedural memory are recruited in the internal simulation when planning ahead. The only difference is that the body is decoupled from the control loop and instead the loop through the world is replaced by a loop using internal models and their predictions as feedback. Together, these representations form the global workspace (this notion of internal models has been termed “second-order embodiment,” c.f. Metzinger 2014).
Koch & Tsuchiya (2007) differentiate attention and consciousness, as both can be present individually and independently of each other. They conclude that different mechanisms are responsible for attention and consciousness. While such a differentiation is of course based on basic definitions, we can indeed identify different mechanisms related to these two phenomena, even though they seem to be related. In reaCog, attending to a specific stimulus is modelled as a specific activation of motivation units. Only if this activation is strong enough and/or active for enough time, can the procedure enter the phenomenal state (section 7, figure 8). Therefore, both attention and the phenomenal aspect of consciousness refer to different, but tightly coupled properties of our system.
10.3 Metacognition
Although in this article we use the term cognition in the strict sense as proposed by McFarland & Bösser (1993), when dealing with metacognition, this definition is no longer generally applicable. Therefore, in this section the term cognition is used in the usual, more qualitatively-defined way. We will describe how the motivation unit network could be expanded to allow our agent to be endowed with different aspects of metacognition. These expansions, however, have not yet been simulated by being implemented into the complete network.
Metacognition, or reflexive consciousness (sometimes called metarepresentation), the second essential domain of consciousness, according to Block (1995, 2001) and Cleeremans (2005), is characterized by Lau & Rosenthal (2011) as “cognition that is about another cognitive process as opposed to about objects in the world” (p. 365).
While the selection of procedures for control of behavior may occur on the reactive level or by application of access consciousness, metacognition in addition is able to exploit information concerning a subject’s own internal states. As a further property, a metacognitive system, when selecting behavior, can represent itself as selecting this behavior (“I make the decision”). Metzinger (2014) classifies this ability as third-order embodiment, where the subject’s own body is “explicitly represented as existing” (p. 274) and the “body as a whole” can turn “into an object of self-directed attention” (p. 275). Thus, metacognition is about monitoring internal states in order to exploit this knowledge for the control of behavior. According to Cleeremans (2005), metacognition may also be used for inferring knowledge about the internal states of other agents from observing their behavior and for communicating a subject’s own states to others.
Let us first focus on the individual agent. What kind of information might be used by a metacognitive system? A typical case discussed in the literature concerns some quality measure of the procedure to be selected. During decision-making, a person, when relying on own knowledge, needs to be able to access his or her own internal state in order to estimate how sure he or she is about the specific piece of knowledge. Cleeremans et al. (2007) use as an illustrative example a system consisting of two artificial neural networks. While the first network learns an input-output mapping of the task, the other network, as a second-order network, learns to estimate a quality measure describing the performance of the first-order network. As the combination of the two networks does not only store information in the complete system, but also contains information about and for the system, the authors conclude that such a system already shows a limited form of metacognition. Such a network, using an additional second-order subnet, might be implemented in our system, too. For example, motivation units could be activated by confidence, or quality values estimated by such a second-order network. Such a situation can indeed be found in the network Navinet. Navinet is used for navigation control tasks and is inspired by work on navigation in ants. In this system, the salience of a stored stimulus guides memory retrieval (Cruse & Wehner 2011; Hoinville et al. 2012). For instance, the decision to choose one of many different food sources is influenced by the internal representation of the learned food quality (Hoinville et al. 2012). As another example, the confidence value of a visual landmark that is to be followed or not might depend on the salience of the visual stimulus, similar to the implementation of a Bayesian-like system. A different example is given by reaCog, which, by exploiting its internal body model, is capable of representing its own body for internal simulation as well as for control of behavior. Thus, at least some basic requirements for metacognition, such as being able to use own internal representations for the control of behavior, are fulfilled, if we, again, leave the phenomenal aspect aside. Below we will, in addition, briefly address the ability of the agent to represent itself.
How may metacognition be suited to support information transfer between different agents? We will not refer to communication using verbal or gestural symbols here. Instead, we want to start with the ability to identify oneself with another agent, or, in other words, to be able to “step into the shoes of the other.” This faculty has been referred to as Theory of Mind (ToM). Central is the notion of being able to attribute mental states to other agents (Premack & Woodruff 1978). A classical example is the “Sally–Anne task”. In this experiment, two subjects observe how a cover hides a piece of candy lying on a table. While one subject, Sally, is outside of the room, the other subject, Anne, is able to observe how the hidden candy is moved to a new location. After the change the candy lies underneath a white cover and not under the black cover, which it did to start with. The crucial test question is put to Anne: where does she think Sally will search for the candy? If Anne points to the white cover she only uses her own current beliefs about the situation, but does not apply a ToM, i.e., she does not take into account what Sally believes—since Sally has not observed the switch. But if Anne points to the original location, the black cover, she is assumed to have a Theory of Mind as she operates on a set of mental states that she ascribes to Sally.
ToM is crucial when an agent needs to capture not only physical objects, but in addition represent other agents. It becomes necessary to explicitly keep track of others’ observations, plans, and intentions. Only such agents that can attribute mental states to other agents can successfully predict their behavior. There are two common explanations to account for how ToM is realized. First, the so-called theory–theory (Carruthers 1996) assumes that there are dedicated, innate, or learned procedures that allow for prediction of internal states and therefore the behavior of others. We want to concentrate on the second main approach, namely simulation theory (Goldman 2005).
Central to simulation theory is the already introduced notion of an internal simulation. As a prerequisite an agent needs an internal model of him or herself. This model can be used (as explained) for planning ahead using internal simulation. But in the same way this model can also be recruited in order to represent another agent. Thereby, other agents may be mapped onto the own internal model that allows simulating the behavior of the other agent. This faculty would enable the agent to derive all sorts of conclusions based on its own representations, such as, for example, current goals or intentions.
In the case of reaCog, we envision an extension that allows mapping another agent onto the already existing internal model. Internal simulation could be used in this context, too. Therefore, the application of such an internal simulation of another agent could lead to an interpretation of the behavior of the other. However, the two theories mentioned do not necessarily exclude each other, as can be shown when regarding the properties of the cognitive expansion further. If the interpretation found via an internal simulation of another agent is new and succeeds in simulating its behavior, the result could be stored in the procedural memory in a similar way as described for reaCog, when coming up with a new solution to a given problem. In this way, a new procedure has been learned that allows for prediction of the behavior of the other agent. As such, application of simulation theory might in the end lead to results that are described as characterizing theory-theory. The faculty of applying a ToM is currently beyond the ability of reaCog as described above, which allows for an egocentric view only. In the following, we will, however, sketch a way in which such a network may be implemented into the architecture of reaCog (for more details see Cruse & Schilling 2011).
Figure 9 shows a possible expansion of reaCog. Two motivation units represent the state “awake” and the state “sleep”, respectively. In the awake state, several sensory and/or motor elements can be activated. These elements may form different contextual groups. To simplify matters, here we focus on two such groups only. One group contains the procedure “grasp” and a memory element representing the visually-given input “position of an object” (relative to the agent), in this case the position of a piece of candy (pos.candy), which is hidden under a cover. We further assume that the agent can also recognize, as a specific kind of object, a conspecific (“partner”), (see Steels & Spranger 2008 and Spranger et al. 2009 for solutions), to whom the agent can attribute properties. These are, in our example, the memory elements “face” and “position”, which stand for the visual appearance and spatial location of the partner to be recognized. Together with the unit “partner” these motivation units form an excitatory network (the dashed connections marked 1A and 1B will be treated later). The procedure “grasp” contains a body-model consisting of an RNN (Schilling 2011) that contains information on the arm used for grasping. This network can be applied to both motor control and recognition of the arm. The former function is symbolized by the output arrow. Concerning the latter function, the body-model is used to minimize errors between the position of the internal model of an arm and the (underspecified) visual input of the arm (e.g., Schilling 2011). If the error could be made small enough, the visual input can be interpreted so as to match the morphology and the specific spatial configuration of the model arm. To symbolize this capability, in figure 9 the procedure “grasp” is also equipped with sensory (visual) input.
The network depicted in figure 9 (disregarding connections 1A and 1B) enables the agent to recognize the position of the candy and to grasp it (“Ego grasp candy”), as indicated by the motivation units marked red in figure 9a. It further allows recognition of the face and the position of the partner. But it does not enable the agent to “put itself into the partner’s shoes”. In other words, the agent is not able to realize that the partner may have his/her own representation of the world. Thus, the capability of a ToM is lacking.
The motivation unit connecting the agent-related elements “pos.candy” and “grasp” has been called “Ego” in the figures. Although not required for the functioning of this network as shown in figure 9a (disregarding connections 1A and 1B), the application of the unit Ego would allow the introduction of a Word-net representing the word “I”. Thus, with this expansion the concept of “I”, as opposed to other agents (e.g., a partner), can be used by our agent, allowing for internal states like “I grasp candy”, and therefore for self-representation.
Unit Ego is, however, necessary in our framework when two units (here “Ego” and “Partner”) share elements, as will be the case in the following example, where we will enable the agent to represent the partner performing a grasping movement. To this end, we introduce mutual excitatory connections between the unit representing the partner and the procedural element “grasp” (dashed excitatory connection 1A, figure 9). In addition, Unit “Ego” and unit “Partner” have to be connected via mutual inhibition (dashed inhibitory connection 1B, figure 9). This inhibitory connection has the effect that only one of the units—either unit “Ego” or unit “Partner”—can be activated at a given moment in time. With these additional connections 1A and 1B, the network can adopt the internal state “Partner grasp candy”. This situation can be represented in the agent’s memory by activation of the motivation units illustrated in figure 9b, highlighted in red. Note that the introduction of connections 1A and 1B does not alter the ability of the agent to represent the situation “Ego grasp candy” addressed above.
The architecture depicted in figure 9, including connections 1A and 1B, has eventually been termed the application of “shared circuits”, since the procedure “grasp” can be addressed by both unit “Ego” and unit “Partner”, which strongly reminds us of properties characterizing mirror neurons. Therefore, application of such shared circuits has been described as “mirroring” (Keysers & Gazzola 2007). Units of the grasp-net (including the target pos.candy) represent the movement and its goal, and thus correspond to representations of a motor act, such as has been attributed to mirror neurons (Rizzolatti & Luppino 2001). The grasping movement in both cases (figure 9a, b) is represented as being viewed by the agent (“Ego grasp candy”, figure 9a) or by the partner (“Partner grasp candy”, figure 9b). This means that there is still no ToM possible for the agent. To enable the agent to develop a ToM, we need another expansion.
To explain this, we will present a simple simulation of the Sally–Anne task mentioned above. Both protagonists, Sally and Anne, may have different memory contents concerning the position of the candy. This means that the agent, in this case Anne, needs to be able to represent some aspects of the memory of her partner, too. Therefore, the memory section representing her partner will be equipped with a memory element representing the position of the candy as viewed by her partner Sally, who left the room (figure 10, connection 2). Both memory elements that have possible access to the procedure “grasp” have to be connected by mutual inhibition, so that only one of these elements can address the procedure at a given time in order to allow for sensible representation of the situation. Now imagine that the subject Anne is either equipped with a network as depicted in figure 9, or that depicted in figure 10. Application of a system as shown in figure 9 means that the agent (Anne) has only one representation of the candy’s position, namely the one seen last. Therefore only this, correct, position can be activated and it is imagined that the partner grasps the correct position—this kind of prediction is observed in children younger than about four years. Anne cannot take into account the likely assumption her partner will make about the location of the candy. In contrast, in a system as presented in figure 10, there is a difference in thinking of oneself grasping the candy or the partner grasping it. When the agent, Anne, imagines herself grasping the candy, she would grasp its position as under the correct cover (figure 10a). If asked to simulate the internal state of her partner, as is required in the case of the Sally–Anne test (figure 10b), the position connected to her partner Sally is used and the agent will rightfully deduct that her partner’s grasp would be directed towards this position—which is wrong, but this fact is not known by her partner. Therefore, the network shown in figure 10 allows for ToM, in contrast to the network shown in figure 9. The critical difference between both networks is that the network shown in figure 10 contains a separate representation of (a part of) the partner’s memory. This means that a comparatively simple expansion of our network shows how the agent could be equipped with the ability to apply ToM.
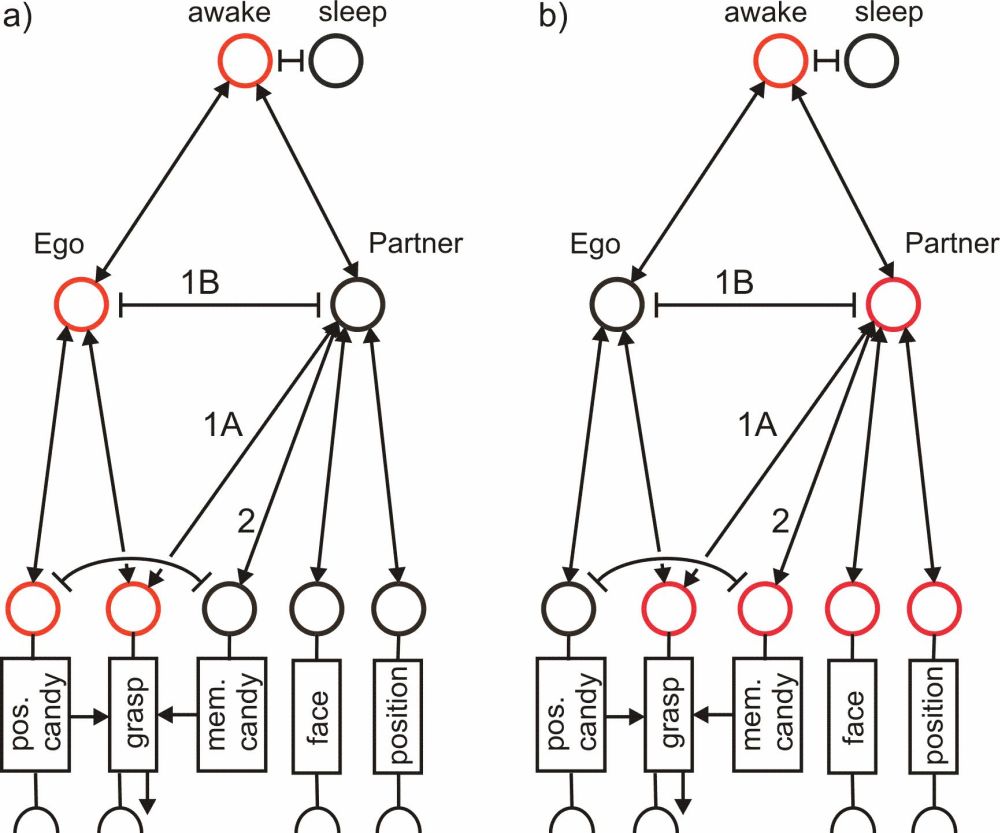 Figure 10: An expansion of the network shown in figure 9, allowing the agent to apply ToM. The expansion concerns the introduction of a new memory element (“mem.candy”) plus connection # 2, which enable the agent to represent the assumed content of the partner’s memory.
Figure 10: An expansion of the network shown in figure 9, allowing the agent to apply ToM. The expansion concerns the introduction of a new memory element (“mem.candy”) plus connection # 2, which enable the agent to represent the assumed content of the partner’s memory.