7 Integration: Feature grouping and segregation
 Figure 5: On the left, we see a textured square overlying a textured background. This is because we automatically group all line segments with the same orientation into one object, and segregate it from the line segments with the orthogonal orientation. The small circle represents the receptive field of a V1 neuron, that would not be able to differentiate between the “figure” and the “background” stimulus, because the line segments within that receptive field are identical. Indeed, V1 responses are identical up to about 100ms after stimulus onset. Beyond that, the two responses start to diverge, however, indicating that the response of the V1 neuron is modulated by the perceptual context of what is within its receptive field (Lamme 1995; Lamme et al. 2000).
Figure 5: On the left, we see a textured square overlying a textured background. This is because we automatically group all line segments with the same orientation into one object, and segregate it from the line segments with the orthogonal orientation. The small circle represents the receptive field of a V1 neuron, that would not be able to differentiate between the “figure” and the “background” stimulus, because the line segments within that receptive field are identical. Indeed, V1 responses are identical up to about 100ms after stimulus onset. Beyond that, the two responses start to diverge, however, indicating that the response of the V1 neuron is modulated by the perceptual context of what is within its receptive field (Lamme 1995; Lamme et al. 2000).
Both in interference phenomena such as brightness or colour shifts and in inference phenomena like the Kanizsa triangle we see some aspects of the integration of information. Visual responses go beyond the encoding of individual pixels, and start to influence each other, either on the basis of more or less hardwired lateral interactions, or on the basis of the incorporation of prior knowledge. In the end, conscious vision seems to be about reaching full integration.[22] We have one visual percept, where all information is combined.[23] This is a property of conscious vision that has interested scientists for a long time. Gestalt psychologists formulated a multitude of laws, along which image elements may be combined into larger wholes (Rock & Palmer 1990; Wagemans et al. 2012). In this grouping process, all features, together with their interactions, inferences, and meanings are combined into a final percept: the thing we see, the whole scene containing shapes, objects, and backgrounds. This is a highly dynamic process in which various Gestalt laws may compete for one interpretation or another, and where subtle changes may influence the meaning of pixels at long distances. We enter the domain of feature integration, grouping, binding and segregation. In short; the domain of perceptual organization.
Two levels of integration may be distinguished, where a subdivision between “base groupings” and “incremental groupings” may be useful (Roelfsema 2006). Base groupings are those that depend on the fact that some feature combinations automatically ride together. An orientation-selective cell in the primary visual cortex, for example, is often at the same time also direction-selective. It may be tuned to particular binocular disparities as well. And it will have a limited receptive field. So the firing of that neuron already goes beyond a one-dimensional feature-detector, beyond the photo-diode. It signals an orientation, moving in a particular direction, at a particular 3D depth, and located in some part of the visual field. Such base groupings exist for many feature combinations, such as colour and shape (e.g., V4 cells), or motion and disparity (e.g., middle temporal, MT, cells).
Another type of base grouping is visible in the feature selectivity of a particular cell, where we may recognize the combination of feature-selectivity of cells at earlier levels. From the start, Hubel and Wiesel recognized that orientation selectivity could be viewed as a convergence of information from retinal ganglion cells lying in a row. The feedforward convergence of information from orientation selective simple cells leads to the receptive field structure of complex cells, which are orientation and direction selective (Hubel & Wiesel 1968). Many higher-level feature-selective cells can be seen as converging information from lower level cells (Tanaka 1996).
Base grouping does not depend on consciousness. The combined feature selectivity of neurons, as well as high-level feature selectivity based on the feedforward convergence of lower-level feature selectivity are still present in anaesthesia or masking (Lamme & Roelfsema 2000; Roelfsema 2006).
Of a very different nature are “incremental groupings”. Here, the information from separate neurons has to be combined to obtain a higher level categorization. A good example is texture based figure-ground segregation, shown in figure 5 (Lamme 1995; Zipser et al. 1996). Here, we automatically perceive a textured square overlying a textured background. This is entirely due to the fact that the centre square is made up of line segments of a particular orientation, different from the line segments that make up the background. There is no luminance difference or any other cue that gives the square “away”. Line segments of one orientation are automatically grouped into a coherent surface—the square—that is segregated from the surface that is formed by line segments of the other orientation—the background. Orientation-selective neurons in V1 typically have small receptive fields, which would only cover a small part of either the figure or background. The grouping of line segments into coherent surfaces, segregating from each other, requires the integration of information from a large set of separate V1 cells. This constitutes “incremental grouping” (Lamme & Roelfsema 2000; Roelfsema 2006).
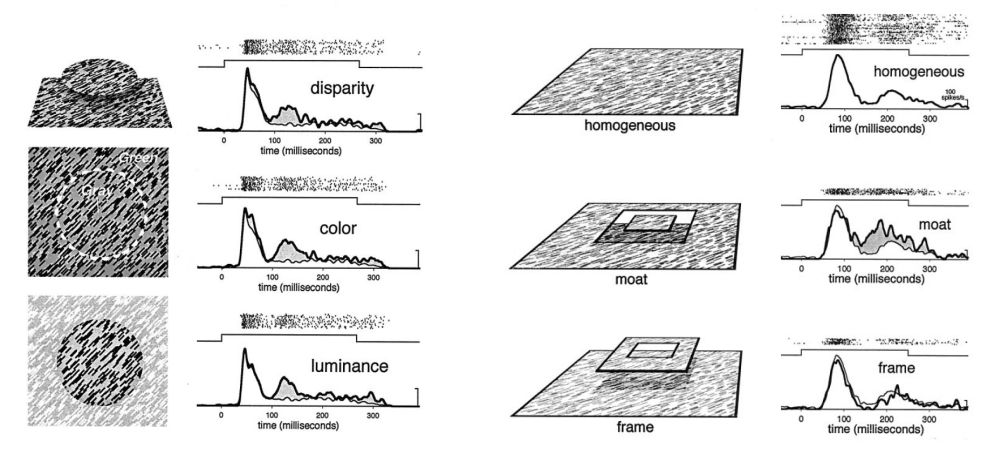 Figure 6: Contextual modulation of V1 responses follows the global perceptual interpretation of images. In all cases, the V1 receptive field is stimulated with the exact same line segments. When these line segments belong to a homogenous background texture, a response indicated by the thin line is given. Left: when the line segments belong to a figure that is defined by differences in disparity, colour, or luminance, the responses are larger. Right: differences in 3D disparity were used so that the patch of texture was either part of a figure square “floating in a moat behind it” or in the background with a “frame” hovering in front of it. The contextual modulation always followed these perceptual interpretations, in that “figure” interpretations always evoked larger responses (Zipser et al. 1996).
Figure 6: Contextual modulation of V1 responses follows the global perceptual interpretation of images. In all cases, the V1 receptive field is stimulated with the exact same line segments. When these line segments belong to a homogenous background texture, a response indicated by the thin line is given. Left: when the line segments belong to a figure that is defined by differences in disparity, colour, or luminance, the responses are larger. Right: differences in 3D disparity were used so that the patch of texture was either part of a figure square “floating in a moat behind it” or in the background with a “frame” hovering in front of it. The contextual modulation always followed these perceptual interpretations, in that “figure” interpretations always evoked larger responses (Zipser et al. 1996).
The neural basis of the integration of image elements into larger units, and the subsequent segregation of such units into figure and ground has been studied extensively at the single unit level, both in anesthetized and awake monkeys. The key finding is that of “contextual modulation”, where the response of a neuron to a particular feature within its receptive field is modulated by the larger perceptual context of that feature (Lamme 1995; Zipser et al. 1996; Lamme et al. 1999). In the example of figure 5, the small circle represents a V1 receptive field, which typically has a size of ~1 degree of visual angle. From the “point of view” of that receptive field, there is no difference between the “figure” or the “background” stimulus: in both cases, identical line segments cover the receptive field, and if the neuron were just signalling the presence of this feature (“left diagonal orientation present”), the responses of this neuron should be identical for the two stimuli. Indeed they are, as shown in the panel on the right, showing fully overlapping responses, until ~100 ms after stimulus onset. At that point, however, the responses for figure and background start to diverge. Apparently, information on the context of the line segments starts to influence the response, so that the response is larger for the “figure” than for the “background” context (Lamme 1995).
 Figure 7: Contour grouping. In all cases shown here, oriented image elements are grouped together to form either a line (left), a circle (center), or an animal (right). They group according to the Gestalt principles of proximity, similarity, and colinearity. These stimuli were also used in neurophysiological experiments, typically showing that elements that group and segregate evoke larger neural responses than isolated or background elements.
Figure 7: Contour grouping. In all cases shown here, oriented image elements are grouped together to form either a line (left), a circle (center), or an animal (right). They group according to the Gestalt principles of proximity, similarity, and colinearity. These stimuli were also used in neurophysiological experiments, typically showing that elements that group and segregate evoke larger neural responses than isolated or background elements.
These kinds of figure-ground modulations follow the perceptual interpretation of scenes to a large extent. For example, when figure-ground relationships are ambiguous, or reversed, the modulation follows the globally-organized percept, rather than local orientation differences or gradients (figure 6, right panel) (Zipser et al. 1996; Lamme & Spekreijse 2000).
The perceptual grouping of image elements into larger units follows certain rules and principles, the formulation of which was the largest contribution of the Gestalt psychologists to modern vision theory (Wagemans et al. 2012). Among these Gestalt laws of perceptual organization are “similarity” (elements that look alike will be grouped), “common fate” (elements that go together in time, e.g., move together, will be grouped), “proximity” (elements that are close together will be grouped), and “good continuation” (elements that lie along a smooth line will be grouped). Contextual modulation of V1 neurons behaves according to these rules, in that elements that share luminance, colour, disparity, orientation, direction of motion, or co-linearity induce facilitatory interactions (figure 6 & 7) (Lamme et al. 1993; Lamme 1995; Kapadia et al. 1995; Zipser et al. 1996; Lamme et al. 2000).
How does Gestalt grouping and segregation depend on consciousness? To some extent, contextual modulation seems to survive during anaesthesia. This is, however, largely limited to fairly short range interactions between neurons, barely beyond or entirely within the receptive field (Allman et al. 1985; Gilbert & Wiesel 1992; Nothdurft et al. 1999). More long-range interactions, and interactions that express more global scene interpretations can only be recorded in awake monkeys (Knierim & Van Essen 1992; Lamme 1995; Kapadia et al. 1995; Zipser et al. 1996). For example, the figure-ground specific modulation of V1 responses shown in figures 5 and 6 (and structure from motion defined figure–ground modulation) is fully absent when monkeys are anaesthetized. At the same time, the orientation and motion selectivity of these neurons (i.e., their ability to categorize certain features) is not affected at all (Lamme et al. 1998a).
Similarly, backward masking disrupts figure–ground modulation. In monkeys, the visibility of texture orientation defined figure-ground targets was manipulated by masking with a stimulus consisting of randomly-positioned texture-defined figures (figure 8). The animals were at chance in detecting the location of the target figure for stimulus-onset asynchronie (SOA) of up to 50 ms (i.e., 50 ms between the onset of the target figure and the mask). At larger SOA’s, behaviour quickly rose to ceiling. Figure-ground contextual modulation followed the same pattern: absent up to and including SOA’s of 50 ms, and increasingly present at longer latencies. At the shorter latencies, however, V1 neurons still responded vigorously to the texture patterns in an orientation-selective manner, showing that lower level classification was still present for unseen orientations (Lamme et al. 2002). Similar results were obtained in human subjects using EEG responses (Fahrenfort et al. 2007).
Contour grouping, as displayed in figure 7, is particularly susceptible to masking. When these displays are temporally alternated, so that each element rotates 900 in successive displays, a strong masking effect is observed.[24] Depending on the angle between elements forming a contour, visibility drops to chance at alternation frequencies between 12 and 1Hz. This implies that the integration of these contours takes between 80 to 1000 ms (Hess et al. 2001).
Zipser used dichoptic masking to render orientation-defined figures invisible. Figure-ground stimuli like those of figure 5 were shown to the two eyes of awake and fixating monkeys, yet with opposite orientations in either eye. As a result, the dichoptically-fused image consisted of cross-like elements, in which a figure was no longer visible.[25] Figure-ground modulation was absent in this case (Zipser et al. 1996). In a similar experiment in human subjects, Fahrenfort used face stimuli that were defined by oriented texture differences. A face was present in each image presented to the two eyes. Yet when binocularly combined, the face disappeared in the fused percept. He compared the neural signals obtained for such stimuli to responses to similar stimuli where binocular fusion resulted in a visible face (figure 9) (Fahrenfort et al. 2012). A striking finding was that visibility (although rigorously checked behaviourally) had no effect on the ability of the Fusiform face area to distinguish between face and non-face stimuli, once more corroborating the independence of categorization responses and consciousness. In addition, invisible face stimuli could be classified from neural responses when training the classifier on visible stimuli and vice versa. The difference between visible and invisible binocular faces was found in the fact that visible faces evoked strong recurrent interactions between the FFA and earlier visual areas, both expressed in the fMRI signal (assessed using psychophysiological interaction analysis with the FFA as a seed), as well as in the EEG signal (showing a larger amount of theta, beta and gamma synchronization, and the presence of figure-ground modulation only in the visible condition).
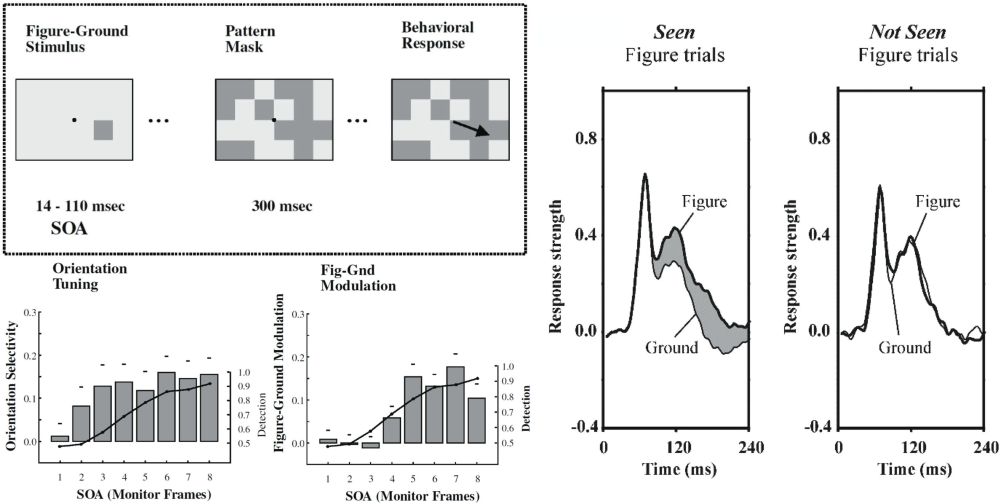 Figure 8: Left, above: textured figure-ground squares (like shown in figure 5) were presented either left or right of the fixation spot, and monkeys had to indicate their position with an eye movement. The figure targets were masked with a pattern of randomly-positioned texture squares. Left, below: the graphs show—for different SOA’s—the ability of monkeys to correctly identify the position of the squares (line graph) versus the strength of either orientation-selective responses or figure-ground modulation (bars). Monkeys do not see the figures at SOA’s of up to 3 frames (~50ms), and likewise, contextual modulation is absent in those cases, whereas orientation selectivity is not (Lamme et al.2002). Right: monkeys had to indicate the presence or absence of textured figure targets by making an eye movement or deliberately maintaining fixation. When figures were not seen, contextual modulation was absent (Supèr et al.2001).
Figure 8: Left, above: textured figure-ground squares (like shown in figure 5) were presented either left or right of the fixation spot, and monkeys had to indicate their position with an eye movement. The figure targets were masked with a pattern of randomly-positioned texture squares. Left, below: the graphs show—for different SOA’s—the ability of monkeys to correctly identify the position of the squares (line graph) versus the strength of either orientation-selective responses or figure-ground modulation (bars). Monkeys do not see the figures at SOA’s of up to 3 frames (~50ms), and likewise, contextual modulation is absent in those cases, whereas orientation selectivity is not (Lamme et al.2002). Right: monkeys had to indicate the presence or absence of textured figure targets by making an eye movement or deliberately maintaining fixation. When figures were not seen, contextual modulation was absent (Supèr et al.2001).
The most direct relation between contextual modulation and consciousness was perhaps demonstrated by Supèr et al. (2001). Monkeys were shown oriented texture figure-ground targets at different locations, and had to signal their presence by making an eye movement towards their positions. Importantly, however, in 20% of the trials, no figure was presented at all, and the monkeys had to maintain fixation on those catch trials for the duration of the stimulus.[26] Indeed the monkeys refrained from making eye movements on catch trials (as they were trained to do). But also on some 8% of trials in which a figure was presented they maintained fixation, as if to say “I did not see a stimulus here”. There was a striking difference in the level of contextual modulation for seen versus not-seen figure targets: modulation was fully absent for not-seen figures (figure 8). Seemingly, on some trials contextual interactions spontaneously fail to develop, and the result is that figure targets were invisible.[27]
That brings us to the question of neural mechanisms. Seemingly, the visual functions of perceptual organization, grouping according to Gestalt laws, and figure-ground segregation all depend strongly on the conscious state, and on the objective (or subjective) visibility and perceptual interpretation of the stimulus. Do these functions have similar neural mechanisms? There has been much debate on the neural connections underlying contextual modulation effects. Given the latency of the effects (typically several milliseconds after the initial categorization or feature response) it was originally hypothesized that they depended on feedback signals from higher-level visual areas (e.g., V4, IT, MT, etc.) toward lower levels (e.g., V1, Zipser et al. 1996). Experiments using cooling or lesioning of higher-level areas gave mixed results. Local inactivation of V2 using GABA injections had no effect on short- to medium-range contextual effects in V1 (Hupé et al. 2001). Cooling area V5/MT, on the other hand, had effects on figure-ground signals in V1, V2, and V3 (Hupé et al. 1998). These effects, however, worked on the early part of the response, and were evoked using stimuli where segregation depended more on contrast differences than on the long-range integration of information (Bullier et al. 2001). Others also found figure-ground effects that were faster than those discussed here (Sugihara et al. 2011). There is thus a whole range of contextual effects, some of which are faster than others, and some of which may depend on feedback while others do not.
There is one counterintuitive aspect of interpreting these results in this way: in fact, feedback connections are not slow, but just as fast as feedforward connections, where both are at about 3.5 m/s (Girard et al. 2001). Horizontal connections that run via unmyelinated fibres in layers 2 and 3 of the cortex are about 10 times slower (Sugihara et al. 2011). Many of the Gestalt principles of perceptual organization are, however, embedded in these slow horizontal connections: V1 cells with a similar orientation preference are selectively interconnected via so-called patchy horizontal fibres. Moreover, these interconnections are strongest for oriented cells that have their receptive fields aligned along their orientation preference. Horizontal connections are also strongest between nearby cells (Gilbert & Wiesel 1989; Malach et al. 1993; Bosking et al. 1997). As such, these horizontal connections thus form the neural substrate of the well know Gestalt rules of “similarity”, “co-linearity”, and “proximity”. A similar arrangement of preferred interconnectivity has been found for motion-direction selective cells in MT (Ahmed et al. 2012), potentially forming the substrate of the grouping principle of “common fate”. Neurophysiological correlates of these grouping principles are relatively fast, however (Knierim & Van Essen 1992; Kapadia et al. 1995).
The figure-ground segregation effects of figures 5, 6, 7, and 8 are among the longest latency contextual effects reported. That may be because they depend on both horizontal and feedback connections. Figure 10 shows the result of an experiment where the complete peri-striate belt of visual cortex surrounding V1 and V2 was subjected to suction lesioning, removing (parts of) areas V3, V3A, V4, V4t, MT, MST, FST, PM, DP, and 7a (Lamme et al. 1998b; Supèr & Lamme 2007). Before the lesion, an oriented texture figure–ground stimulus evoked elevated activity in all neurons responding to the figure elements. Response modulation was even somewhat stronger, and occurred earlier at the boundary between figure and background. This was followed by a sort of “filling in” of enhanced activity between the boundary regions. We thus see an incremental process, starting with boundary segmentation and followed by surface segmentation. Similar findings have been reported in humans using combined EEG and TMS (Wokke et al. 2012).
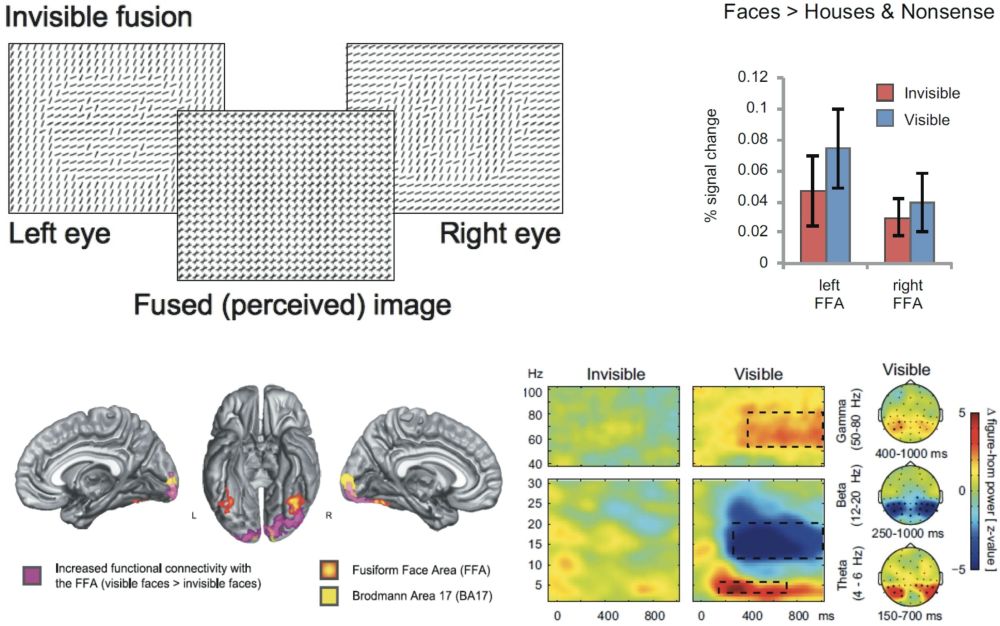 Figure 9: Top left: texture-defined faces were presented in either eye of subjects, yet with different orientations of line segments. As a result, the face was not visible in the fused percept (compare manipulation of figure 1). By using other orientation combinations, the same design could also result in a visible face (not shown). Top right: category-specific responses in the FFA did not differ for visible or invisible faces. Below: visible faces are characterized by strong recurrent interactions between FFA and earlier visual areas (left), and by strong synchronous activity in the theta, beta, and gamma bands (right). From: Fahrenfort et al. (2012).
Figure 9: Top left: texture-defined faces were presented in either eye of subjects, yet with different orientations of line segments. As a result, the face was not visible in the fused percept (compare manipulation of figure 1). By using other orientation combinations, the same design could also result in a visible face (not shown). Top right: category-specific responses in the FFA did not differ for visible or invisible faces. Below: visible faces are characterized by strong recurrent interactions between FFA and earlier visual areas (left), and by strong synchronous activity in the theta, beta, and gamma bands (right). From: Fahrenfort et al. (2012).
After the lesion, the boundary enhancement remained, which may indicate that texture boundary detection mechanisms do not depend on feedback from higher visual areas and hence are mediated by horizontal connections within V1, or by recurrent interaction with V2. The centre modulation, where the figure elements are “neurally elevated” from the background elements, was completely abolished after the lesion, indicating that these figure-ground signals do depend on recurrent interactions between V1 and higher-tier areas. This finding was modelled on a realistic neural network of spiking neurons, indeed formalizing the idea that local orientation contrast—and hence the boundary between figure and ground—is mediated by inhibitory horizontal interactions between oriented receptive fields, whereas the figure–ground signal depended on excitatory feedback interactions trickling down from higher to lower areas (Roelfsema et al. 2002). Recently, laminar recording of figure-ground signals in V1 confirmed this idea (Self et al. 2013). These results show that the long-latency figure-ground segregation effects depend on incremental interactions mediated by both horizontal and feedback connections. That may be the reason why they are most vulnerable to anaesthesia, masking, and other manipulations of consciousness.
Tononi modelled several neural architectures in order to find the connection parameters that fulfil the requirements for achieving maximally-integrated information. The optimal architecture consists of neurons that each have specific and different connections patterns, yet are sufficiently interconnected for each neuron to be able to connect to another via a few steps. Uniformly, or strictly modularly organized networks are less optimal. The thalamo-cortical system fits these requirements very well. On the one hand, neurons should be interconnected, otherwise information is not integrated. On the other hand, too much interconnection leads to a loss of specific information, as all neurons start doing the same thing, which happens in epilepsy or deep sleep—states that are indeed accompanied by a loss of consciousness (Tononi 2004, 2008, 2012). The contextual modulations that have been explored here seem to exactly express these properties: on the one hand, the neural responses are very specific, in that the major part of the response is driven by the features that are within the (small) receptive field. But on the other hand, the integration of these features rides on top of that response as a moderate modulation, expressing perceptual integration that may cover a large spatial extent, yet never even beginning to fully override the information carried by the neuron. In other words, visual neurons have categorization as their main priority, yet they also integrate these categories at some point in their response. That is the moment in time where the seed for conscious perception is laid (Lamme 2003, 2006, 2010a, 2010b).
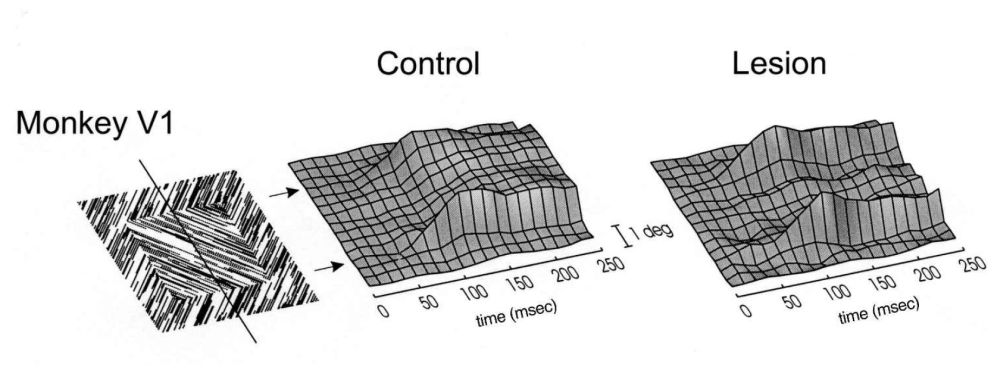 Figure 10: Contextual modulation (i.e., figure–ground responses, see figure 5) for various positions of the receptive field of V1 neurons (vertical axis), and extending over time (horizontal axis). In an intact monkey, modulation arises first at the figure-ground boundary, followed by a “filling-in” of the boundaries. After a lesion to the peri-striate belt of the visual cortex, only the boundary modulation remains, while filling-in has been abolished (Lamme et al. 1998a).
Figure 10: Contextual modulation (i.e., figure–ground responses, see figure 5) for various positions of the receptive field of V1 neurons (vertical axis), and extending over time (horizontal axis). In an intact monkey, modulation arises first at the figure-ground boundary, followed by a “filling-in” of the boundaries. After a lesion to the peri-striate belt of the visual cortex, only the boundary modulation remains, while filling-in has been abolished (Lamme et al. 1998a).