4 Categorization: From low to high level features
Above, I used the example of seeing a face. What does seeing a face mean, in terms of the visual functions being executed? Recognizing a face first of all entails that one identifies the stimulus as belonging to the class “faces”, as opposed to any other class of stimuli, such as “animals”, “teapots”, “houses”, or “letters”. This is a process of categorization. Intuitively, categorization seems a key property of consciously seeing and recognizing a face. It is not, however. Since the first findings of blindsight it has been recognized that categorization can occur fully independently of conscious sensations (Weiskrantz 1996; Boyer et al. 2005). Patients without awareness of stimuli in the blind part of the visual field can nevertheless categorize these stimuli, as long as the categorization is framed in a two-alternative forced choice: is it a square or a circle, is it moving upwards or downwards, is it red or green, vertical or horizontal? In such cases, patients’ responses fall well above mere chance, indicating that the categorization of stimuli in two distinct classes is still functioning, and hence does not necessarily require consciousness.[10]
Categorization is the main function of cortical visual neurons, in that each neuron is feature-selective: it only responds to a stimulus when that stimulus possesses certain visual features. A Nobel prize was awarded for this finding, as it is fundamental to the operation of the visual cortex (Hubel 1982). It ranges from low level features such as spatial frequency, orientation, direction of motion, or colour to higher-level features such as the geometry of a shape or the class of an object. Each feature-selective neuron can be seen as doing a simple, often one-dimensional categorization: it signals “vertical orientation”, “moving upwards”, or “rectangular shape” (Lamme & Roelfsema 2000). Face-selective neurons shout “face!” (Oram & Perrett 1992). The categorization responses of visual neurons are so fundamental to their operation that they are fully independent of consciousness: most neurons are equally feature selective in anaesthesia as they are in the awake condition (Dow et al. 1981; Snodderly & Gur 1995; Lamme et al. 1998a). Feature-selective responses of neurons are mediated via feedforward connections, and visual categorization proceeds along these feedforward connections in an unconscious way (Lamme et al. 1998b; Lamme & Roelfsema 2000).
Additional evidence dissociating categorization from consciousness comes from a multitude of sources. Unseen stimuli in backward-masking are also categorized, as can be judged from the specific priming effects they may evoke. For example, a fully masked digit 7 may speed up (or slow down) responses to categorizing a second digit (or number word) as either being above or below 5, showing that the masked and unseen number (the 7) is categorized according to its numeric value (Dehaene et al. 1998).[11] Many similar examples exist. Moreover, it has been shown that masked and hence unseen stimuli evoke category-specific responses from the brain, either in the form of selective single unit responses (Rolls & Tovee 1994; Macknik & Livingstone 1998), or in the form of selective activation or category-selective regions such as the Fusiform Face Area (FFA) (figure 1) (Moutoussis & Zeki 2002; Kouider et al. 2009),[12] or in the Visual Word Form Area (Dehaene & Naccache 2001)—indicating that they are categorized up to the level of face vs non-face or word vs non-word (Dehaene et al. 2004). There is a large body of literature covering the unconscious processing of emotional valence in either faces or words (Straube et al. 2011).
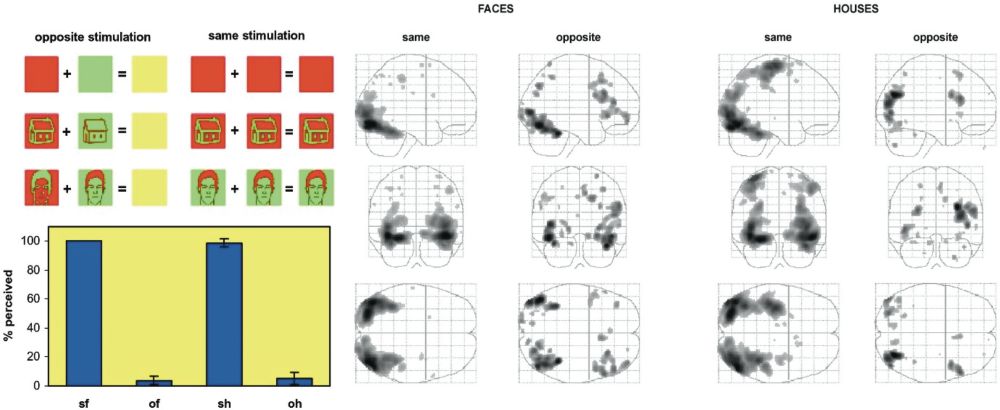 Figure 1: Faces and houses were made invisible using dichoptic masking—i.e., presenting oppositely coloured versions to each eye. Regardless of (in-)visibility, these faces and houses evoked selective activations of category specific regions of the brain (from: Moutoussis & Zeki 2002).
Figure 1: Faces and houses were made invisible using dichoptic masking—i.e., presenting oppositely coloured versions to each eye. Regardless of (in-)visibility, these faces and houses evoked selective activations of category specific regions of the brain (from: Moutoussis & Zeki 2002).
Particularly far-reaching levels of unconscious categorization have been reported for behaviourally or socially relevant stimuli. Tools evoke selective activation of the dorsal stream areas—and selective priming effects—when made invisible with CFS (Fang & He 2005; Almeida et al. 2008). Faces that have their eyes turned towards the viewer break from CFS sooner than faces that are turned away—a finding that is probably explained by the fact that faces turned towards the viewer pose a very relevant or even threatening social signal (Gobbini et al. 2013). Similarly, the gender of naked bodies is processed during CFS (Jiang et al. 2006). Also, the mismatch between object categories is identified for stimuli made invisible using CFS: scenes with mismatching objects (e.g., a cook taking a chess-board out of the oven instead of a dish) break from CFS sooner than matching scenes (Mudrik et al. 2011).
The latter finding is related to various non-visual “categorization” processes that occur for invisible stimuli: it has been shown that masked stimuli travel throughout the brain, even reaching high-level areas involved in inhibitory cognitive control, response error selection, or evidence accumulation, exerting high-level cognitive effects (Van Gaal & Lamme 2012). So invisible stimuli not only activate visual categorization processes, but also activate extremely high-level and very abstract categories such as the stimulus being a “stop signal”, an “error”, or “evidence for a right button press”.
From a neural perspective, categorization is feature selectivity, which may range from very simple to highly complex features and categories. This kind of categorization proceeds entirely independent of consciousness.[13] So how does conscious recognition differ from categorization? To answer this question, we have to take a closer look at categorization responses. What a face-selective cells does, is to categorize a face as belonging to the class of faces versus non-faces. That’s all. When we consciously see a face, however, we do much more than this: we classify the stimulus as a face, but at the same we identify its shape, colour, identity, and emotional expression. So we distinguish between “that brown face of my sad-looking friend Peter” and very many other faces—and also between that face and millions of other potential visual stimuli.
Gulio Tononi uses the metaphor of a photo-diode to illustrate the point (2008, 2012). For a photo-diode a black screen is different from a white screen. That’s a distinction it can make. The photo-diode carries information about the brightness of the screen, so its signal carries one bit of information (or a few bits, depending on its sensitivity). For us, however, consciously seeing a black screen is very different. Seeing the black screen implies that we distinguish it from a grey screen, a red screen, a black table, a green house, a pink face, a dog, a sound, a feeling, or any other sensory event that would have been possible. Consciously seeing the black screen thus carries a huge amount of information, as it excludes an almost endless set of alternative sensations. And that makes seeing “that brown face of my sad-looking friend Peter” very different from what a face-selective neuron does when it signals “face”. The neuron behaves much like the photodiode, in that it signals presence or absence of a feature along a single dimension. That is because neurons tend to combine feature-selectivity with invariance for other features: a face-selective cell signals faces regardless of colour, size, identity or expression (Rolls 1992).[14]
Tononi proceeds from a photo-diode to the photo camera as a metaphor for explaining another central feature of conscious sensations (2004, 2008, 2012). He argues that the critical difference between a conscious representation in the human mind and what happens in a camera is that in the camera information is distributed and not integrated. Each and every pixel signals a particular level of luminosity, but it does so entirely on its own. It does not “know” what other pixels are doing. To the camera it would not matter if all the pixels were cut apart and became separate cameras. Conscious sensations, on the other hand, are integrated.
It thus seems that to find for visual operations that are more closely linked to consciousness, we must look for something beyond basic categorization. We must look at processes where the individual pixels in our camera—the billions of neurons each signalling particular features—are interacting, and are integrating their information.