3 Internal representation
In addition to using the loop through the environment itself, some form of internalization is a prerequisite for any kind of planning. Therefore, specific internal representations[5] are necessary for a cognitive system. This is well in line with the embodied perspective, because from an evolutionary point of view internal models are not at first disconnectable from a very specific function, and they work in service of a specific behavior (Glenberg 1997). Internal models have, in this sense, co-evolved with behavior (Steels 2003). An early representation is the representation of one’s own body, and such a representation becomes meaningful early on, in simple control tasks like targeted movements or sensor fusion.
3.1 Body model
In reaCog we introduced an internal model of the body. This model is realized as an RNN (Schilling 2011) and has a modular structure (Schilling & Cruse 2007; Schilling et al. 2012). The overall model consists of two different levels. On the top level the whole body and the structure of the insect are represented in an abstract way. Only on the lower level are the details filled in. The lower level consists of six leg networks. Here, for each leg the functional structure of the joints and the limb is captured. In this way this level of representation can be used for motor control and provides detailed information about joint movements. On the higher level, the structure of the body and the legs is represented in an abstract form, i.e., only the footholds of the legs appear on this level. Figure 2 shows the different parts of the body model (drawn in blue). The body model is modular. It comprises a holistic system that is realized as an RNN (figure 5, see Schilling 2011; Schilling et al. 2012 for details).
The body model is used during normal walking, meaning that the system is still in the reactive mode, in forward as well as backward walking or when negotiating curves. It coordinates the movement of the joints and delivers the appropriate control signals for the Stance-networks. As explained above, overall the system is redundant, with twenty-two DoFs in the whole body structure, and this makes deriving consistent control signals for all the joints a difficult problem that can’t be computed directly, but rather requires application of additional criteria (e.g., for optimizing energy consumption). In our approach, which uses the internal body model, we employ the passive motion paradigm (von Kleist 1810; Mussa-Ivaldi et al. 1988; Loeb 2001). Consider the body model as a simulated puppet of the body (figure 5) that is pulled by its head in the direction of the goal (figure 5b, pull_fw). This information on the target direction could be provided by sensory input, e.g., from the antennae or vision, in the form of a target vector (figure 2, sensory input). When pulled in this direction, the whole model should take up this movement and therefore the individual legs currently in stance should follow the movement in an appropriate way. The induced changes in the joints can be read out and applied as motor commands in order to control the real joints. In backward or curved walking, the body model has only to be pulled into a corresponding direction (in backward walking using the vector attached to the back of the body model, pull_bw (figure 5b). In this way we obtain an easy solution to the inverse kinematic problem as the body-model represents the kinematical constraints of the body of the walker. It restrains the possible movements of the individual joints through these constraints, and only allows possible solutions for the legs standing on the ground, thereby providing coordinated movements in all the involved joints.
The body-model is also connected to the sensors of the walking system and integrates the incoming sensory information into the currently-assumed state of the body as represented in the body-model. In this way the body-model is able to correct noisy or incorrect sensory data (Schilling & Cruse 2012). Overall, the main task of the body model is pattern completion. It uses the current state and incoming sensory data to come up with the most likely state of the body that fulfils the encoded kinematic constraints. In this way, the model can also be used as a forward-model, meaning that, given specific joint configuration, the model can predict the three-dimensional arrangement of the body, for example the position of the leg tips. The predictive nature of the model is crucial as it allows exploiting the model for planning ahead (see below). It is important to note that while we do not want to claim the existence of such a model in insects, the functions of internal models are prediction, inverse function, and sensor fusion, and these can all already be found in insects.
3.2 Representation of the environment
Of course, internal representation should also contain information on the surroundings. We started with a focus on the body and want to extend this network in a way that reflects how the environment affords (Gibson 1979) itself to the body, i.e., a focus on interaction with the environment.
As an example of how the reaCog architecture could be extended to include representation of meaningful parts of the environment, we want to briefly sketch an expansion of Walknet that would allow for insect-like navigation (“Navinet” Cruse & Wehner 2011; Hoinville et al. 2012). Navinet provides an output that will be used by the body-model explained above to guide walking direction. Due to the network, the agent can make an informed decision about which learned food source she will visit (e.g., sources A, B or C), or if she is travelling back home or not (Outbound, Inbound, respectively). The output of Navinet is, in this way, on the one hand tightly coupled to the control of walking and the representation of the body. On the other hand, Navinet is constructed using motivation units in the same way as the walking controller, and those motivation units take part in the action-selection process. Importantly, Navinet (like desert ants) shows the capability of selective attention, since it is context dependent and only responds to learned visual landmarks in the appropriate context, i.e., when related to the current active target food source. The structure of the motivation-unit network is sketched in figure 4. Examples of possible stable internal states are (Forage – Outbound – source A – landmarks associated with source A) or (Inbound – landmarks associated with Inbound), for instance. As an interesting emergent property, Navinet does not presuppose an explicit “cognitive map”. Such a map-like representation has been assumed necessary by several other authors (Cruse & Wehner 2011). How learning of food source positions and food quality is possible has been shown by Hoinville et al. (2012).
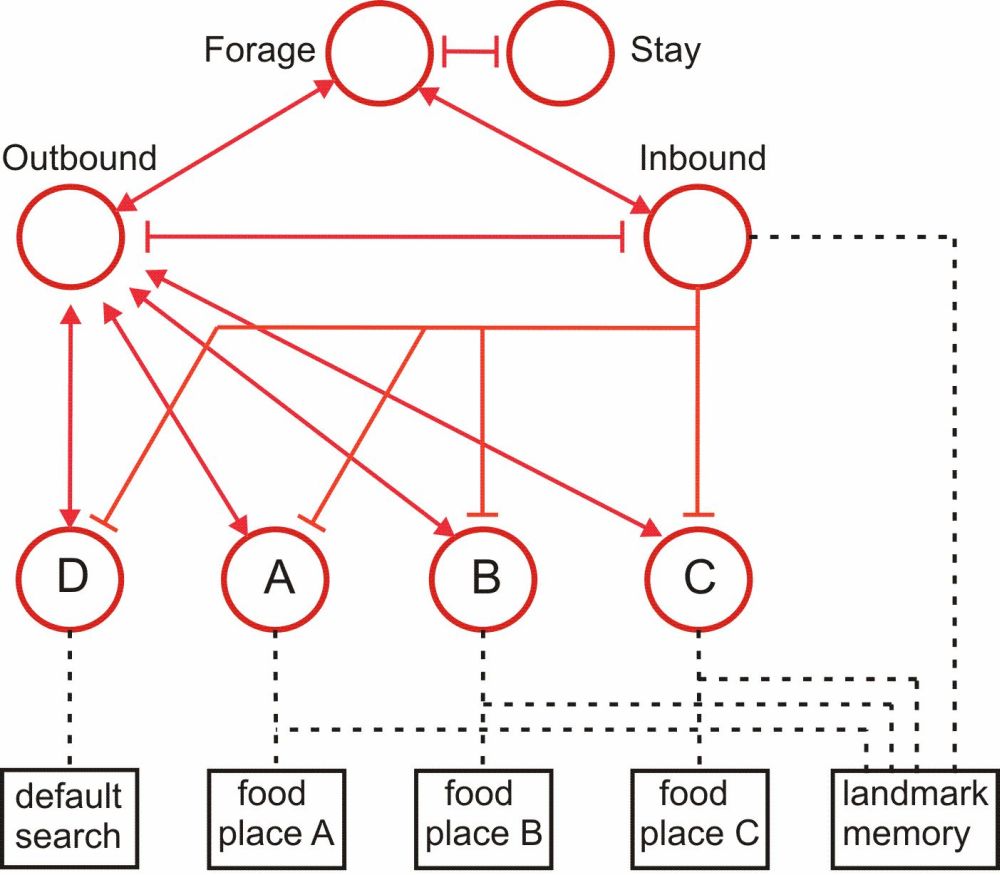 Figure 4: Motivation unit network of Navinet for the control of ant-like navigation. Unit Outbound controls travel from the home to a food source (A, B, C) or a default search for a new source (D). Unit Inbound controls travel back to the home. Memory elements (black boxes) contain position and quality of the food source (A, B, C) or information on visual landmarks (landmark memory).
Figure 4: Motivation unit network of Navinet for the control of ant-like navigation. Unit Outbound controls travel from the home to a food source (A, B, C) or a default search for a new source (D). Unit Inbound controls travel back to the home. Memory elements (black boxes) contain position and quality of the food source (A, B, C) or information on visual landmarks (landmark memory).