9 Indeterminate contents and the phenomenal precision principle
As I mentioned, an attended .20o gap looks the same size as an unattended .23o gap. Of course the comparative percept—the gaps looking the same—is illusory. But what about the percepts of each gap, considered separately? Is the percept of the attended .20o gap illusory? Is the percept of the unattended .23o gap illusory? I argued that we would need a better reason than we have to suppose that one but not the other is illusory. And I claimed that we should not suppose that both are illusory. The option I have argued for is that both are (or rather can be in normal circumstances) veridical. As I mentioned, the simplest perceptual representations contain two elements, a singular element that represents an individual item and a perceptual “attributive” in Burge’s terminology that attributes a property to that individual item (2010). In the gap-size case, the perceptual attributive attributes sizes to gaps. A veridical percept attributes a size to a gap only if the gap has that size. In order for the attributed property to apply to both gaps, that property will have to be “intervalic”, i.e., a somewhat imprecise property—for example, the property of being within the range of .20o to .23o (inclusive of endpoints). Since both gaps are in that range, both percepts are veridical (in respect of gap size).
Perhaps a probabilistic treatment of these ranges of values is in order? But how can one justify one probability distribution rather than another without making assumptions about whether the attended gap is seen more veridically than the unattended gap? For example, to say that the unattended percept of the .nno gap represents the gap as most likely to be .nno, whereas the attended percept represents the same gap as most likely to have some other value is to regard the unattended percept as more veridical than the attended percept. A probabilistic treatment would perhaps pass the sufficient reason test though if the same probability were attributed to both ends of the range.
It will be useful to move back to the example of contrast. The data portrayed in Figure 7 comes from the bottom right of Figure 9. Figure 9 contains four comparisons, each of which is keyed to one of the four little squares between the patches. If one fixates on one of the squares, the patch to the left of the square attended is the same in apparent contrast as the patch on the right unattended. The 22% patch can be unattended—in which case it has the same apparent contrast as the 16% patch when it is attended, or the 22% patch can be attended in which case it has the same apparent contrast as the 28% patch when it is unattended. So different veridical percepts of the 22% patch could represent it as the same as patches that are 6% more or 6% less in contrast.
Consider the contrast phenomenology of an attended percept of the 22% patch. That phenomenology is the same as the phenomenology of a 28% patch unattended. Assuming that there is not normally a phenomenology that specifies what one is and is not attending to, a matter discussed above in section 7—the phenomenology of a 22% patch attended does not carry the information of whether it is the phenomenology of a percept of a 22% patch or of a 28% patch. So in order for both percepts with that phenomenology to be veridical, the representational content would have to be at a minimum 22%-28% (inclusive of 22% and 28%).
However, there is a determinate difference in phenomenology between percepts of the 22% patch and the 28% patch when serially fixated and attended as you can verify by looking at Figure 9. (There are larger differences of this sort to be described later and as I mentioned in section 3, inhomogeneities in the visual field produce larger differences of this sort.) I believe that this determinate difference is appreciable if one moves one’s attention while fixating the little square but the difference is even more obvious if one moves fixation as well as attention.
The 22% and 28% patches look determinately different if one is attending to and foveating (looking right at) each in turn. So if representationism is true, there can be veridical representational contents of 22%-28% only if the phenomenal precision of the percepts of the patches seen attended and foveated is narrower than the phenomenal precision of at least one of the percepts seen in the periphery with only one attended. This is a version of what I called the phenomenal precision principle in section 2. If two things look the same (veridically) when seen in peripheral vision with at least one unattended, but the same two things look determinately different—also veridically— when seen foveally and attentively, then the phenomenal precision of the attended and foveal percepts must be narrower than at least one of the prior percepts. And we can guess that it is the unattended prior percept that has to be less precise.
Recall that perceptual representations that are imprecise in that they attribute ranges can still be fine-grained. Suppose for example that a percept attributes a broad range of sizes to a gap of .10o-.50o. That is a different representational content from .11o-.51o, and that is different from .12o-.52o. So our ability to see small differences can be based on absolute representation even if perception is imprecise. But if the representational contents of the foveal percepts almost totally overlap, as with .11o-.51o .12o-.52o, how could those representational contents ground the determinately different phenomenologies?
Consider an analog for inattentive peripheral perception of color in which there is a red patch on one side and a blue patch on the other and the subject fixates in the middle. Suppose—and as far as I know this is science fiction—that there is some distribution of attention such that the two patches seen briefly and inattentively in the periphery can look the same and look red-blue and have the representational content red-blue. I don’t mean reddish blue. I mean indeterminate as between central red and central blue or in between. They could be red, they could be blue, or they could be in between. Since attentive foveated percepts of red and blue in normal conditions are determinately different from one another (and from other colors) in phenomenology, the representational contents of red and blue seen foveated, attentively (and leisurely), would have to be more precise than the supposed contents seen peripherally, inattentively (and briefly). Otherwise there would be increasing precision in phenomenology without increasing precision in representational content and representationism cannot allow that.
In short, representationism requires that inattentive peripheral perception be less precise representationally than attentive and foveal perception.
Now here is the striking fact: there is evidence that peripheral inattentive perception of many properties is not less representationally precise than foveal attentive perception. This conclusion conflicts with the application of the phenomenal precision principle to the cases at hand. I have already discussed the peripheral vs foveal aspect of this point and I will go over some of the evidence for the attentional component in section 11 below.
I will explain the argument just sketched in more detail. But first I must discuss a piece of the puzzle, the notion of a just noticeable difference.
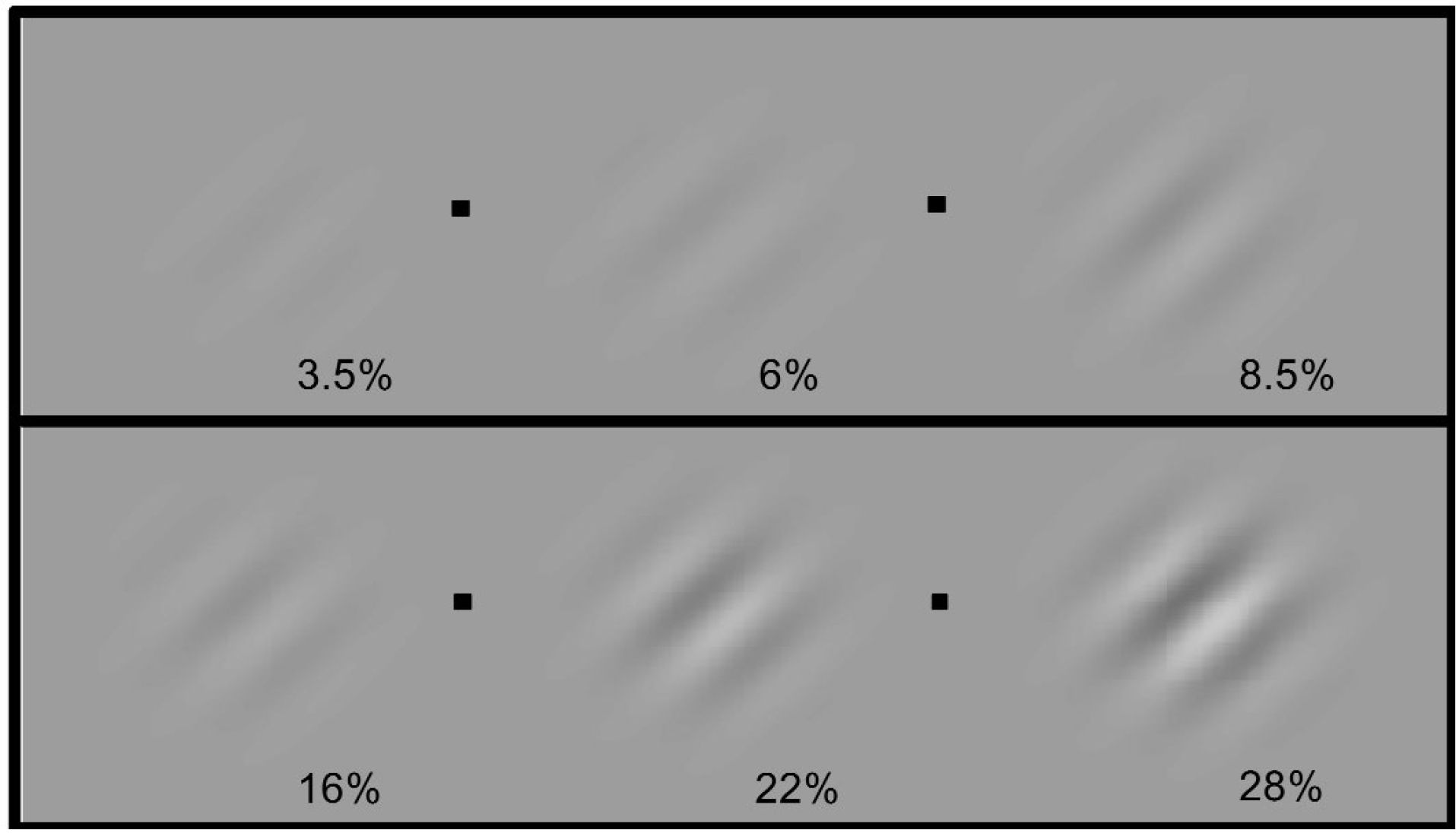 Figure 9: If one maintains fixation on one of the 4 little squares while varying attention to the patches on either side of the square, the patch to the left of the square seen with attention has the same appearance as the patch to the right without attention. I am grateful to Marisa Carrasco for this figure.
Figure 9: If one maintains fixation on one of the 4 little squares while varying attention to the patches on either side of the square, the patch to the left of the square seen with attention has the same appearance as the patch to the right without attention. I am grateful to Marisa Carrasco for this figure.