3 The inhomogeneous visual field
Although this article is mainly about differences in perception wrought by differences in attention, it will be helpful to start with a discussion of similar issues that arise independently of attention because of the massive inhomogeneities in the visual field. I will discuss the perception of contrast. The visual system is much more sensitive to differences in luminance than to luminance itself and contrast is a matter of luminance differences. (Luminance is a measure of the light reflected from a surface.) Contrast can be defined in a number of different ways, all ways of capturing the average difference in luminance between the light and dark parts of an array. The four patches in Figure 2 have roughly equal apparent contrasts if one is fixating the cross though there is substantial variation among persons in comparative sensitivities in the visual field. But the top patch has a 30% contrast and the bottom patch has a 15% contrast. (To fixate the cross is to point your eyes at it.) Vision in the lower visual field (the South) has about 65% better sensitivity than vision in the upper visual field on average along the “vertical meridian” (the vertical line through the fixation point) for points of equal eccentricity. And sensitivity is better along the horizontal meridian than the vertical meridian, that is East and West have higher sensitivity than points of equal eccentricity in the North and South. This sensitivity advantage is about 63%. Marisa Carrasco suggests that the advantage of the horizontal over vertical meridians probably has to do with the presence of more relevant information on the horizontal meridian (Carrasco et al. 2001). These differences in sensitivity manifest themselves phenomenologically in differences among patches required for equal apparent contrasts. It takes a 30% contrast patch in the North to phenomenologically match a 10% contrast patch in the East at the equal eccentricity depicted in Figure 2. Performance asymmetries along these lines have been observed for gap size, spatial frequency (roughly density of stripes), orientation discrimination, texture segmentation, letter recognition and motion perception. Performance asymmetries of this sort have been shown in comparisons between an on-screen stimulus and a stimulus from the recent past in visual short term memory for 1-3 seconds, albeit at a slightly lower level (Montaser-Kouhsari & Carrasco 2009). These differences are thought to be due to anatomical asymmetries (Abrams et al. 2012).
I will assume that the percepts of North and East have the same contrast phenomenologies when seen (simultaneously) in peripheral vision. Of course the fact that they don’t look different does not prove that they look the same. And their looking the same does not prove that the phenomenology of each of the two patches is the same— as we know from the phenomenal Sorites problem (Morrison 2013). However, the fact that they look the same is evidence that they are the same phenomenologically and we would need a reason to resist that conclusion. Similar issues will be taken up later in section 8 and 10.
I take it as obvious that the North and East patches are determinately different in apparent contrast when sequentially foveated and attended. The fact that the percepts are sequential makes it unlikely that we are misled about the determinate difference by any analog of the “beats” one hears when guitar strings vibrate at slightly different pitches. (I will return to this issue in section 10.)
North and East look the same in peripheral vision and different in foveal vision. How could this be explained in terms of representational content? The only representational explanation I can think of would be based on the idea that the content of foveal representation of contrast is more precise than the content of peripheral representation of contrast. However, as I will explain below, there is evidence that the representation of contrast in the fovea is the same in precision as the representation of contrast in the periphery. So the burden is on the representationist to explain the difference between foveal and peripheral experience of contrast without appeal to a difference in representational precision. I will now turn to a much longer version of the argument which does not have the form of a burden of proof argument but which makes use of the notion of phenomenal precision.
 Figure 2: If you fixate (i.e., point your eyes at) the plus sign, these four different patches should look roughly equal in contrast at normal reading distance (roughly 15 inches away). The one above the horizontal meridian has twice the contrast of the one below the meridian (30% vs 15%). The two patches on the horizontal meridian have 10% contrast. It takes a 30% patch in the North to match the 10% patch equidistant from the plus sign in the East. Much of the work of investigating this phenomenon comes from Marisa Carrasco’s lab. See Cameron et al. (2002) and Carrasco et al. (2001). Note that there is a large degree of variation from person to person so the patches may not look exactly the same in contrast to you. (The patches are called “Gabor patches” or sometimes just gabors.) Thanks to Jared Abrams for making this figure for me. @copyright Ned Block
Figure 2: If you fixate (i.e., point your eyes at) the plus sign, these four different patches should look roughly equal in contrast at normal reading distance (roughly 15 inches away). The one above the horizontal meridian has twice the contrast of the one below the meridian (30% vs 15%). The two patches on the horizontal meridian have 10% contrast. It takes a 30% patch in the North to match the 10% patch equidistant from the plus sign in the East. Much of the work of investigating this phenomenon comes from Marisa Carrasco’s lab. See Cameron et al. (2002) and Carrasco et al. (2001). Note that there is a large degree of variation from person to person so the patches may not look exactly the same in contrast to you. (The patches are called “Gabor patches” or sometimes just gabors.) Thanks to Jared Abrams for making this figure for me. @copyright Ned Block
I claim that when you fixate on and attend to the cross, both your perception of the North patch and your perception of the East patch normally veridically represent the contrasts of those patches despite the fact that one sees them only in peripheral vision. Many details cannot be seen in peripheral vision but what can be seen is seen veridically in normal circumstances. Of course the comparisons are illusory: patches that are different in contrast look the same. But the issue I am raising is whether the individual percepts of single patches are illusory. One reason to think there is no illusion is that the same kind of differences in perception caused by spatial inhomogeneities in the visual field occur in all percepts due to temporal inhomogeneities—that is, random noise in the visual system that differs from percept to percept. Any two percepts of the same items at the same point in the visual field with the same degree of attention are likely to differ in apparent contrast (and other properties) due to these random factors. It is hard to see a rationale for supposing that spatial inhomogeneities engender illusion while claiming the opposite for temporal inhomogeneities. And claiming that both engender illusion would make most perception illusory.
This is where my appeal to Tyler Burge’s recent book comes in (2010). As Burge notes, we can explain the operation of constancy mechanisms in perception only by appeal to their function in veridically representing the distal environment. And that function precludes perception being mostly non-veridical.[4]
I will say more by way of justification of the verididality claim later but for now let us accept that claim and think about the consequences for representationism. Note that the veridicality assumption is meant to apply to non-categorical perception of properties that admit of degrees and is not meant to apply to categorical perception. Afraz et al. (2010) showed that gender neutral faces are more likely to look male in some areas of the visual field and female in others. The veridical percept in this case would represent the gender-neutral faces as androgynous so both of the percepts described are non-veridical. Many varying magnitudes such as size and contrast are not perceived categorically in this way so there is no corresponding “reality check” for such magnitudes. (Some magnitudes such as orientation may mix categorical and non-categorical perception.)
A percept that attributes a property to an item is veridical only if the item has the attributed property. However, the veridical percepts of North and East (when fixating the cross) attribute the same contrast property since they look the same in contrast. Let us ask what the content of the (veridical) percepts of North and East are when one is fixating the cross and they look the same in contrast. That is, what contrast would the percepts of North and East attribute to those patches? Since East is a 10% patch and North is a 30% patch, and both are veridical, it follows that the percepts have to attribute the same contrast to them (since they look the same). What attributions would be the same and also veridical? The patches would have to be represented as having a range of contrasts between 10% and 30% at a minimum. That is, the minimal imprecision in the representation is 20%, the imprecision of a representation of 10%-30% contrast (including the endpoints).
Now let us ask what the contrast-content is when we fixate (and attend to) the East patch, the 10% patch. If the precision is the same as in peripheral perception (i.e., 20%), the percept could have a content of 10% plus or minus 10%, i.e., 0% to 20%. (A 0% contrast patch would be invisible, so presumably imprecision ranges should be weighted towards higher absolute values of the magnitude perceived. Variability in perceptual response increases with the absolute value of the magnitude perceived—one form of the Weber-Fechner Law. This is a complication that I will mainly ignore.) And for similar reasons, if the precision is the same in foveal as in peripheral perception, the contrast content of the percept of the North patch when one fixates it would be 20%-40%.
The representational precision is 20% but what about the phenomenal precision? Can we make sense of this idea? As with all that is phenomenal, no definition is possible. The best that we can do is indicate a phenomenon that the reader has to experience for him or herself. One type of example exploits the difference between an object close up and the same object at a distance. An object may look to have the same properties at both distances but with different precisions. An object may look crimson close up but merely red (and not any particular shade) at a distance.
If the phenomenology of perception is grounded in its representational content and if there is such a thing as phenomenal precision, an increase in phenomenal precision depends on a corresponding increase in representational precision. Representational precision can be indexed numerically—a representational content of the length of something as 1 inch—2 inches (i.e., between 1 and 2 inches) is more precise than a representational content of it as 1 inch—3 inches. According to representationism, phenomenal precision is just the phenomenology of the precision of representational content. We experience a percept with representational content of 1 inch-2 inches as having more (i.e., narrower, smaller range) precision—as being more phenomenally determinate— than we experience a percept with representational content 1 inch—3 inches.[5]
Note that I am not saying that we can always ask whether a certain item of phenomenology is more precise or less precise than a certain representational content (though I think there are some cases where this does make sense). What I am saying is that a representationist has to hold that a difference in phenomenal precision is grounded in a difference—of the appropriate sign and magnitude—of representational precision.
Here is the application of these ideas about precision: Foveate North and East in turn (i.e., serially). I claim that they look determinately different. According to what I mean by looking determinately different, for items to look determinately different, their phenomenologies cannot be almost completely overlapping. Why is lack of almost complete overlap important? The representational contents of perception can be very imprecise even though discrimination is fine grained. One might represent one patch as 10%-30% in contrast and another patch as 10.5%-30.5% and as noted by Jeremy Goodman (2013) that would in principle allow for discrimination between them. If the phenomenal precision of these percepts is also very wide, then the phenomenologies of these percepts would not be determinately different from one another—given what I mean by these terms.
Don’t get me wrong: I do think that items can look different on the basis of different but overlapping contents. For example, if one is foveating a patch and simultaneously sees a patch of the same contrast in peripheral vision, the two will look different in contrast. Each of the two percepts can be veridical (even though the comparative percept is not). And being veridical and being of the same contrast, the intervallic contents have to overlap.
You may be skeptical about whether there is such a thing as phenomenal precision and whether there is such a thing as phenomenal overlap. But a representationist should not be skeptical. If one’s visual experience represents one length as between 1 inch and 2 inches and a second as between 1 inch and 3 inches, then it is hard to see how a representationist could deny that the phenomenal character that is grounded in the first is more precise than the phenomenal character that is grounded in the second. And if one patch is represented as 10%-30% in contrast and another patch as 10.5%-30.5% the representationist would need a good reason to claim that the phenomenologies did not almost completely overlap. Given that representationism would seem to be committed to phenomenal precision and phenomenal overlap, it would seem legitimate to assume them in an argument against representationism.
North and East look the same when fixating the cross and determinately different when fixating (and attending) to each in turn. What does this fact tell us about representational and phenomenal precisions? The phenomenal precision of perception of contrast must be narrower (i.e., smaller range, greater precision) in foveal vision than in peripheral vision—in order to explain why North and East look the same in respect of contrast in peripheral vision but determinately different in foveal vision. Even if we cannot make sense of an absolute value of phenomenal precision at least we can make sense of differences in it. We might think of this as a phenomenal precision principle:
If two things look the same in peripheral vision and determinately different in foveal vision, then the phenomenal precision of foveal vision is narrower (smaller range) than that of peripheral vision.
At least for one of the foveal percepts, and why would one have narrower precision but not the other? And so according to the representationist, representational precision must be narrower in foveal than in peripheral vision as well—otherwise there would be a difference in phenomenal precision that was not grounded in a difference in representational precision. (The peripheral perceptions are simultaneous and the foveal perceptions are serial. The inhomogeneities described here hold both for simulaneous and serial presentations, albeit at a slightly reduced level in serial presentations. This has been shown separately for inhomogeneities in the visual field (Montaser-Kouhsari & Carrasco 2009) and for the attentional effects to be discussed later (Rolfs et al. 2013)).
Note that as far as the doctrine of supervenience of phenomenology on representation is concerned, North and East could look the same but still be represented differently. The grounding formulation says: With qualifications to be mentioned: different representational contents require different phenomenologies; supervenience speaks to the converse only. Qualifications: there may be different representational parameters, only one of which is the ground of the relevant phenomenology. So there could be multiple representational realizations of a single type of phenomenal state where the representational differences reflect differences in the parameters that are irrelevant to grounding. And: phenomenology might be grounded in representational content even though the grain of phenomenology is coarser than that of representational content. So there might be differences in fine-grained representational content that do not make a phenomenal difference.
No one would object to the idea that pure dispositions like fragility or solubility could be grounded in different molecular structures in the case of different substances. And physicalists about phenomenology have held that the underlying basis of a common phenomenology might be one physical state in humans and another in robots. However, I have argued that the grounding framework reveals that physicalists should not acknowledge this kind of multiple realizability (2014a). Applied to this case, the idea is that a representationist account should give us a representationist answer to the question of what it is in virtue of which the phenomenology of the peripheral percepts of North and East are the same. Phenomenal sameness requires representational sameness as a ground. And that representational sameness in this case has to be a precision range of 10%-30% or more.
Of course the notions of phenomenal precision and almost complete overlap of phenomenologies are obscure. The methodological situation we are in is that we have a well-developed science of perception but very little science of the phenomenology of perception. One response—very common until recently—is to avoid issues of phenomenology like the plague. But the time may be ripe to try to leverage the science of perception to get some insight into the phenomenology of perception. And that project cannot help but start with some vague intuitive notions.
Here is where we are: foveal percepts of the contrasts of North and East are determinately different in phenomenology but peripheral percepts of them are the same in phenomenology so the phenomenal precision of North and East, each seen foveally is narrower than the phenomenal precision of North and East seen peripherally. If representationism is to avoid a difference in phenomenal precision that is not based in a corresponding and commensurate difference (of the right direction) in representational precision, then representational precision has to be narrower in foveal than peripheral perception. That is, the representationist should hold that peripheral perception is less representationally precise than foveal perception.
Here comes the punch line: Robert Hess & David Field (1993) compared the discrimination of the locations and contrasts of patches of different contrasts. They presented triples of patches in which the middle patches could differ from the flankers in (1) locations and (2) contrasts. They asked subjects two questions concerning each triple: whether the middle patch differed from the flanker patches in location and contrast. What they found was that discrimination of locations falls off greatly in the periphery but discrimination of contrasts does not. They conclude (pp. 2664, 2666), “… we show that for normal periphery, elevated spatial uncertainty is not associated with elevated levels of contrast uncertainty at any spatial scale… A change in positional error of a factor of 14… from the fovea to the periphery has an associated contrast error that does not significantly increase over the same range of eccentricities.” The graphs are striking: position error increases greatly with peripherality of the stimuli but contrast error is a flat line. See Figure 3 for one of the figures that illustrates this fact. As far as I can tell, this result is widely accepted. Even a critical reply (Levi & Klein 1996) says “Their results (discussed below) show that position discrimination is selectively degraded in the periphery, while contrast discrimination is not affected.” Levi and Klein dispute the alleged explanation of the result, not the result.
Note that I am taking the fact that contrast discrimination does not diminish in peripheral vision to be evidence that representational precision does not decrease in peripheral vision. Hess & Field (1993) describe a model of the result in terms of constant “uncertainty” for contrast across the visual field but increasing uncertainty for location. Their concern is whether the subjects’ visual representations produce locational errors as a result of “undersampling”. They argue that undersampling should affect contrast errors too. And because it does not, they conclude that the explanation is “uncalibrated neural disarray”: “We propose that, for reasons as yet unknown, the periphery, unlike the fovea, has not undergone sufficient self-calibration to resolve all of its innate anatomical neuronal disorder…” (p. 2669). But we don’t have to buy into neural disarray to accept the observation that contrast uncertainty does not decrease in the periphery.
We feel that foveal attended perception is “crisp”, i.e., high in precision but for some properties—contrast and probably gap size, spatial frequency (stripe density) and speed—there is some reason to think that foveal and peripheral perception are equally precise. The resolution is that some properties—e.g., location—really are represented more imprecisely in the periphery than in the fovea (by a factor of 14). (And some properties seem to be represented more precisely in the periphery, e.g., flicker rate for some spatial frequencies; Strasburger et al. 2011). So we can’t think of peripheral perception as imprecise in regard to all properties we can see. And for the properties that do not decline in precision in the periphery, the representational point of view doesn’t seem to work very well.
Acuity is lower in the periphery than in foveal vision. Anton-Erxleben & Carrasco (2013) describe five mechanisms that jointly explain the decrease in acuity with eccentricity. Cone density and the density of the retinal ganglion cells that process cone signals decrease with eccentricity. In addition, average receptive fields are larger in the periphery. (The receptive field of a neuron is the area of space that a neuron responds to. See glossary.) So the elements of a grid will not be visible in the periphery if they are too finely spaced (i.e., if the spatial frequency is too high). To compensate for this, Hess & Field used only very coarse grids in the periphery. So what the result suggests is that contrast uncertainty does not increase in the periphery—for grids that one can actually see in the periphery.
But why do the behavioral results reflect on representational precision rather than phenomenal precision? The anatomical asymmetries that are the probable basis of the inhomogeneities discussed here are bound to affect unconscious perception in the same way as conscious perception.
The Hess & Field result shows a kind of homogeneity in the visual field in regard to contrast but as I have emphasized in regard to the phenomenon of Figure 2, the visual field is inhomogeneous in regard to contrast. How are these compatible? The inhomogeneities in Figure 1 reflect contrast sensitivity whereas the homogeneity showed by Hess & Field reflect contrast precision.
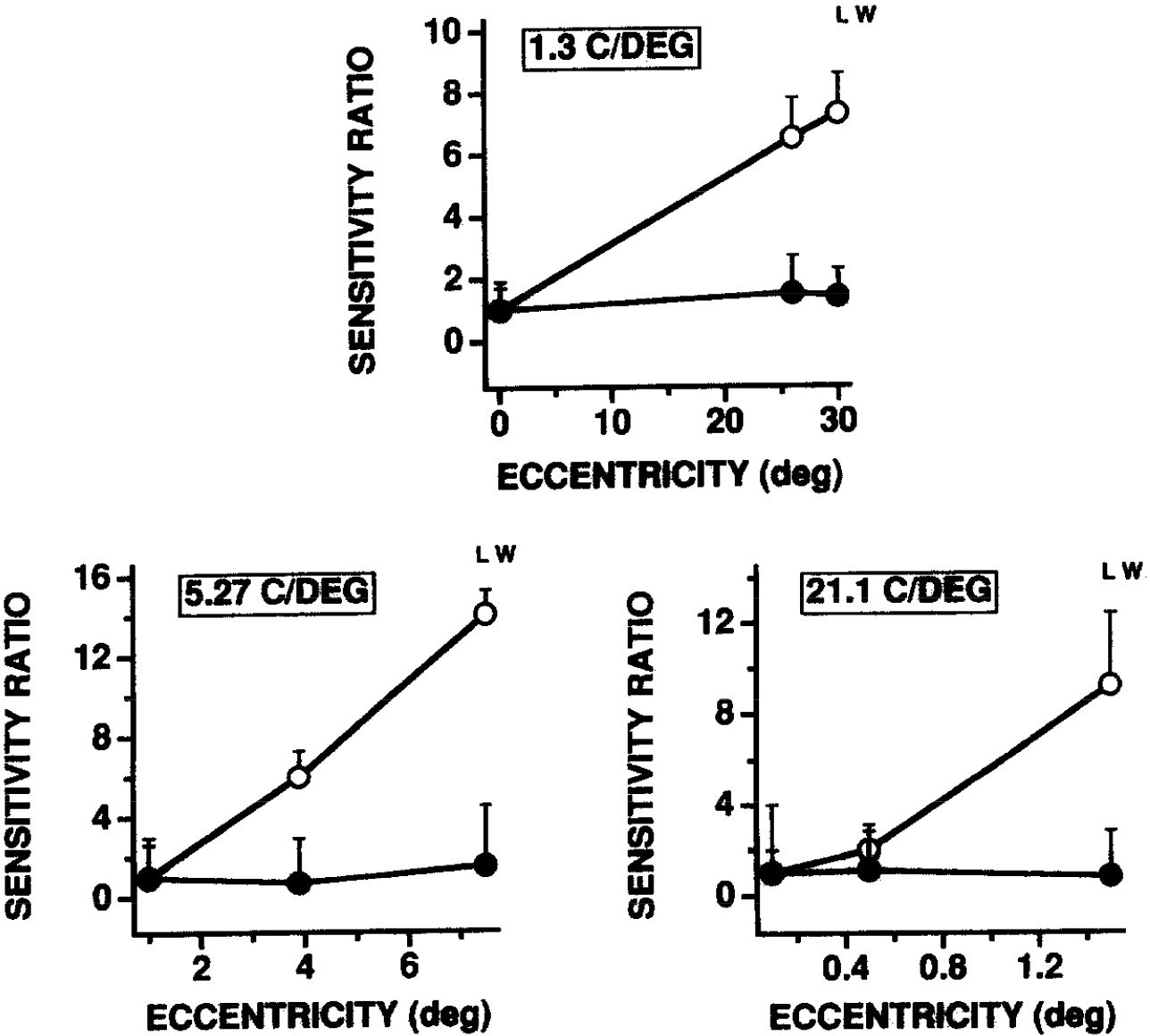 Figure 3: This is one of four graphs from (Hess & Field 1993) showing the comparison between the sensitivity to contrast as compared with the sensitivity to location. The Y-axis represents foveal sensitivity divided by peripheral sensitivity so a value of more than 1 represents greater foveal sensitivity. The solid dots represent contrast sensitivity whereas the open circles represent location sensitivity. The top graph shows sensitivity up to 30 degrees from the line of sight for a very coarse grid of 1.3 cycles per degree. The bottom two graphs show sensitivity for finer grids but at much lower eccentricities. (Coarse grids are visible in the periphery but fine grids would look like a uniform gray surface in the periphery.) Foveal discrimination thresholds are given an aribitrary value of 1. (This is referred to in the article as the values being “normalized”.) What this figure and the other 3 figures show is that contrast sensitivity for grids that are coarse enough to see is the same in the periphery as in the fovea but location sensitivity is much worse in the periphery. Reprinted with permission of Vision Research.
Figure 3: This is one of four graphs from (Hess & Field 1993) showing the comparison between the sensitivity to contrast as compared with the sensitivity to location. The Y-axis represents foveal sensitivity divided by peripheral sensitivity so a value of more than 1 represents greater foveal sensitivity. The solid dots represent contrast sensitivity whereas the open circles represent location sensitivity. The top graph shows sensitivity up to 30 degrees from the line of sight for a very coarse grid of 1.3 cycles per degree. The bottom two graphs show sensitivity for finer grids but at much lower eccentricities. (Coarse grids are visible in the periphery but fine grids would look like a uniform gray surface in the periphery.) Foveal discrimination thresholds are given an aribitrary value of 1. (This is referred to in the article as the values being “normalized”.) What this figure and the other 3 figures show is that contrast sensitivity for grids that are coarse enough to see is the same in the periphery as in the fovea but location sensitivity is much worse in the periphery. Reprinted with permission of Vision Research.
Here is the argument summarized:
The peripheral percepts of North and East, being the same in contrast phenomenology, are the same in contrast-representational contents—if phenomenology is grounded in representation.
The peripheral percepts of North and East are both veridical; that is, North and East have the properties attributed to them in peripheral perception.
Given veridicality and the difference between North and East in actual contrast, the representational contents of the peripheral percepts must be rather imprecise. Since North is 30% and East is 10%, and since the content characterizes both, the peripheral representational contrast-content has a precision range of at least 10%-30%.
Foveal percepts of North and East—one at a time— are determinately different in phenomenology
The phenomenal precision principle: If two things look the same in peripheral vision and determinately different in foveal vision, then the phenomenal precision of foveal vision is narrower (smaller range) than that of peripheral vision.
So the phenomenal precision of the foveal percepts of North and East must be narrower than that of the peripheral percepts of these patches.
Representationism requires that a difference in phenomenal precision be grounded in a commensurate difference in representational precision.
So representationism requires that the foveal representational precision be narrower than the peripheral representational precision. However the experimental facts suggest maybe not.[6]
Conclusion: there is some reason to think that the phenomenology of perception is not grounded in its representational content.
The same argument applies to views that hold that there is a kind of “phenomenological representational content” that emanates from the phenomenology of perception (Bayne 2014; Chalmers 2004; Horgan & Tienson 2002). If there were such a thing, it would have to be precise enough to properly reflect phenomenology but imprecise enough to handle the veridicality considerations raised here. And the argument presented here suggests that can’t happen.
The premise that I think needs the most justification is 4. Do we really have enough of a grip on what it is for percepts to be determinately different in phenomenology to justify the idea that the foveal percepts do not have almost completely overlapping phenomenal characters?
Given the problem with 4, I should remind the reader that I started with an argument that did not appeal to phenomenal precision. North and East look the same in peripheral vision and determinately different in foveal vision. How could this be explained in terms of representational content without appealing to a difference in representational precision between fovea and periphery? This argument has the usual problem of a burden of proof argument but it has the advantage of avoiding the obscurity of phenomenal precision.
Another more introspective route to the same conclusion derives from the point mentioned at the beginning that it is natural to feel that the phenomenology of seeing the contrast between lines and spaces foveally differs in precision from seeing the same lines peripherally. The foveal percept seems more “crisp” than the peripheral percept. If this intuitive judgment is correct, there is a discrepancy between the precision of phenomenology and the precision of representational content.
I think this argument gives the reader a pretty good idea of the dialectic of the paper though the paper is more concerned with the issue of change in precision due to differences in attention than with peripherality.
Worth Boone has argued against my point of view using two-point thresholds of tactile discrimination (2013).[7] As I will explain, I think some of the issues he raises actually support my conclusion.
Boone noted that there are large differences in representational determinacy (precision in my terminology) between tactile acuity as measured by two-point thresholds at various points on the body but that—contrary to what I have said— the precision of the phenomenology matches the precision of the representational content.
First, what are two-point thresholds? “Subjective” two-point thresholds are based on one or two sharp points (e.g., pencil points) being placed at constant separations at various body parts, with subjects reporting whether it feels like there are two points or one point. Objective two-point thresholds are measured by stimulating the skin with either one or two sharp points and observing to what extent the subjects are able to discriminate between these stimuli. Objective thresholds are based on whether there actually are two rather than one point whereas subjective thresholds are based simply on the judgments themselves, independently of their accuracy. The subjective method shows extremely high variability within a single subject on the same body part for a variety of reasons. The objective method has a number of paradoxical features that I won’t go into but if you are interested you can read a short article dramatically titled “The Two-Point Threshold: Not a Measure of Tactile Spatial Resolution” (Craig & Johnson 2000).
However, a recent review (Tong et al. 2013) suggests better measures of tactile acuity that confirm Boone’s point that tactile acuity varies enormously from one part of the skin to another. A glance at a graph in the Tong, et. al. paper reveals that acuity on the tip of the finger is about 5 times that of the palm and about 20 times the acuity on the forearm.
We can ask: is the phenomenology of these perceptions as imprecise as the representational content? Boone says yes but he is judging the phenomenology of two-point perception. That method is doubly illicit, first because it is unclear that two point discrimination is a measure of anything tactile. Second, the two point judgments may simply reflect the representational contents rather than or in addition to the phenomenology, contaminating the verdict on the very point at issue. If you ask someone how determinate their phenomenology of a two point stimulus is, they may simply be reporting how sure they are they are perceiving two points rather than one. The latter is suggested by considerations of representational “transparency” or “diaphanousness” of experience (Stoljar 2004)[8]. As Thomas Metzinger puts it, we “look through” the experience to its object (2003, p. 173). If so, the phenomenology of judging one vs two may be contaminating the judgment of the precision of the percept.
So I will ask again: Do the differences in phenomenological precision between fingertip and palm and between fingertip and foream perception differ by factors of 5 and 20? The question is not well formed: we cannot ask about either phenomenological or representational precision without specifying what is being represented.
To get a better question, let us focus on the perception of location. Representational locational imprecision does vary with location on the body. The explanation of the variation is that the number and spatial distribution of sensory receptors that feed into a single sensory neuron (i.e., the receptive field of the sensory neuron) varies widely over the body.[9] Is there a matching change in the phenomenal precision with regard to location? If there were a massive decrease in representational precision of location from fingertip to forearm without a corresponding decrease in phenomenal precision, we would have a violation of grounding (of a different kind from those already discussed). I suggest you put a single pencil point on your finger tip and then on your palm and forearm. (Or if you have a helper, do them simultaneously.) If there is a five-fold or twenty-fold difference in phenomenological precision of location it should be appreciable with any stimulus. My own introspective judgment is that there is little or no difference in precision of representation despite the five-fold difference between the fingertip and palm and 20-fold difference between the fingertip and forearm. I am pretty sure that the percepts are not determinately different. No doubt people differ both in these experiences and in their introspective access to them. And with all difficult phenomenal judgments, contamination by theory is no doubt a major source of variability.
If my judgment is right, we have a case of a difference in representational precision without a corresponding difference in phenomenal precision. In the visual case just mentioned, we have evidence for a difference in phenomenal precision without a corresponding difference in representational precision. Taken together, the cases suggest a considerable disconnect between perceptual phenomenology and perceptual representation.
The conclusion of this section is that there is some reason to think that there is no representational content of perception that either grounds or is grounded by the phenomenology of perception—what it is like to perceive.
The reader may wonder how there could be such a disconnect between the phenomenology of perception and its representational content. I mentioned the fact that grip accuracy is about the same in the far periphery (70o off the line of sight) as it is close to the line of sight (5o) despite the fact that conscious vision is extremely weak in the far periphery. Conscious vision is a distinct system from the system that underlies the fine details of perceptually guided action. Though I am not alleging that the system underlying conscious perception is distinct from the system underlying perceptual representation, the upshot of this paper is that they are partially distinct.
In what follows, I will be arguing that facts about attention motivate a similar argument for a discrepancy between the phenomenology of perception and its representational content. The reason I went through the argument based on inhomogeneities first is that the issues are straightforward compared with the corresponding issues concerning attention. Attention is a complicated phenomenon about which there is a great deal of disagreement, so the rest of the paper has many twists and turns. The argument form as presented so far will not resume until section 8.